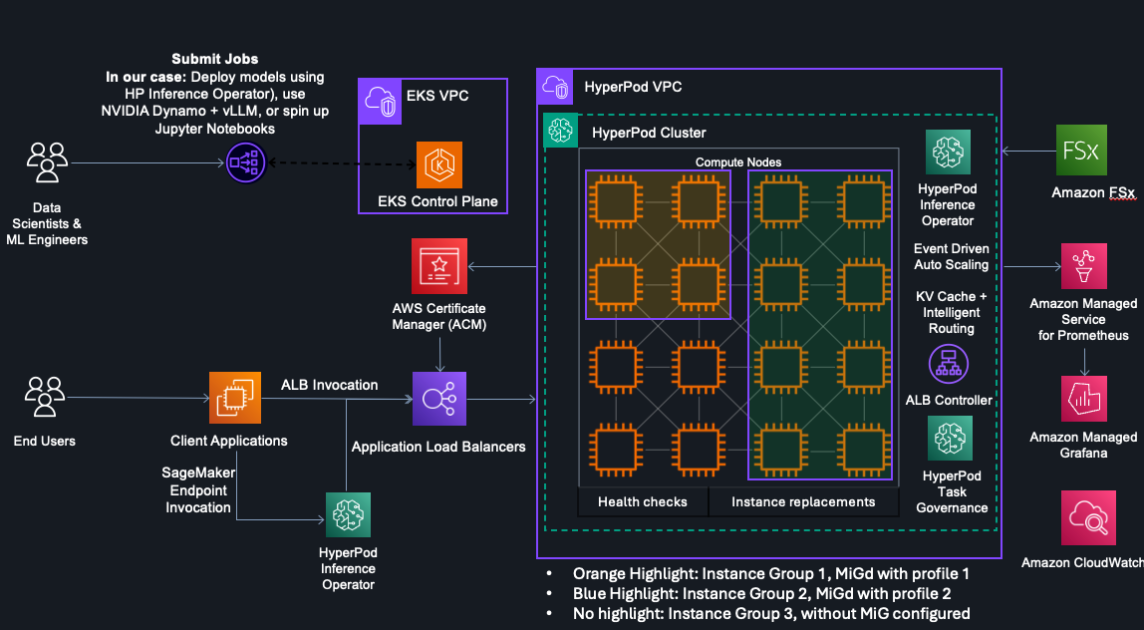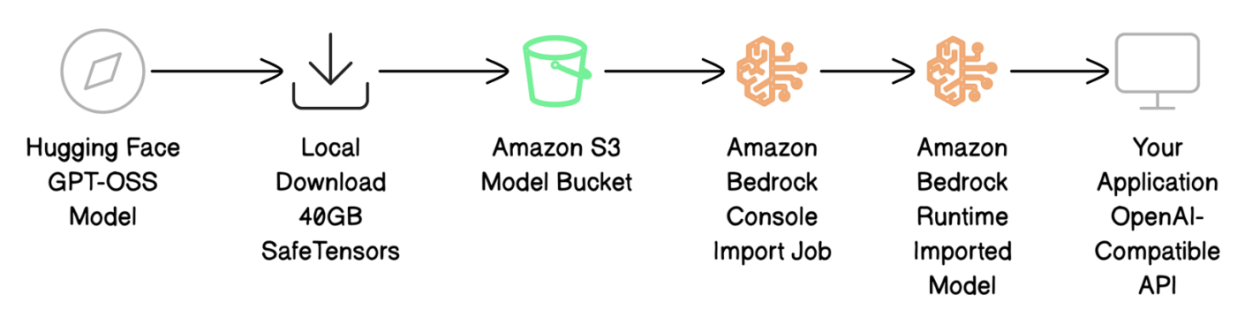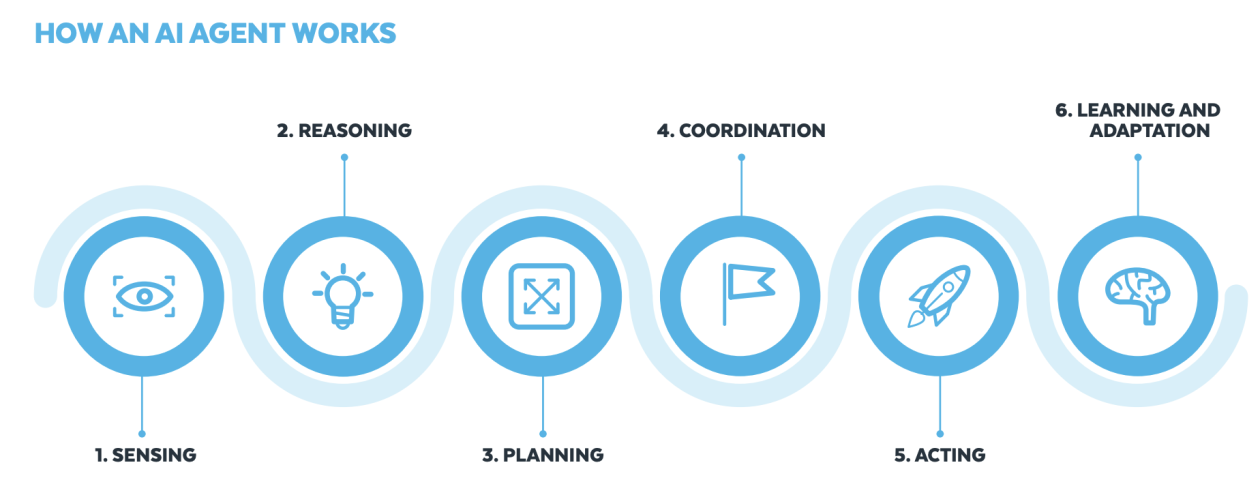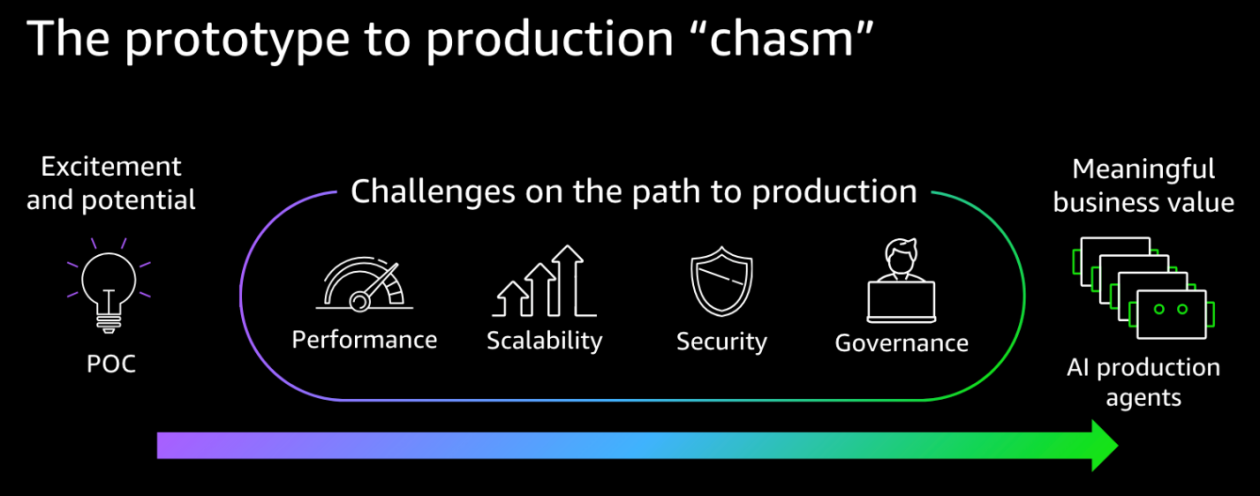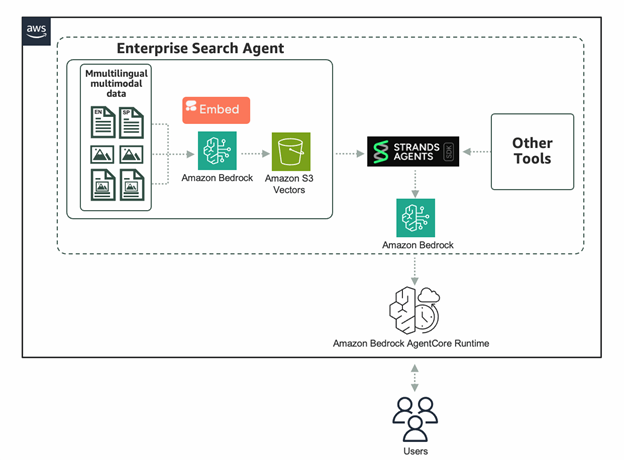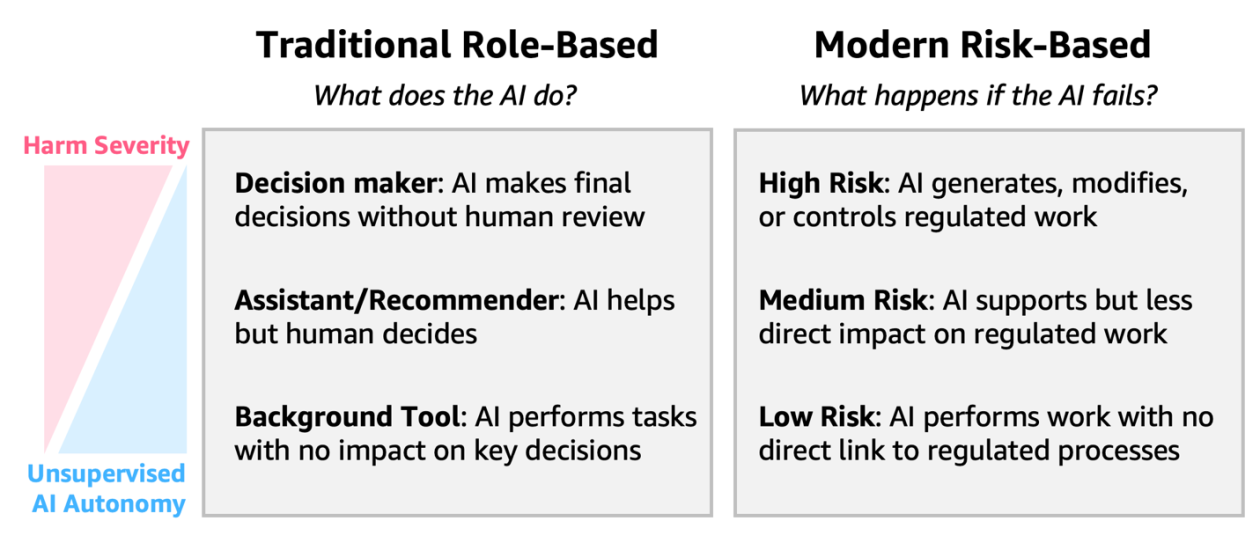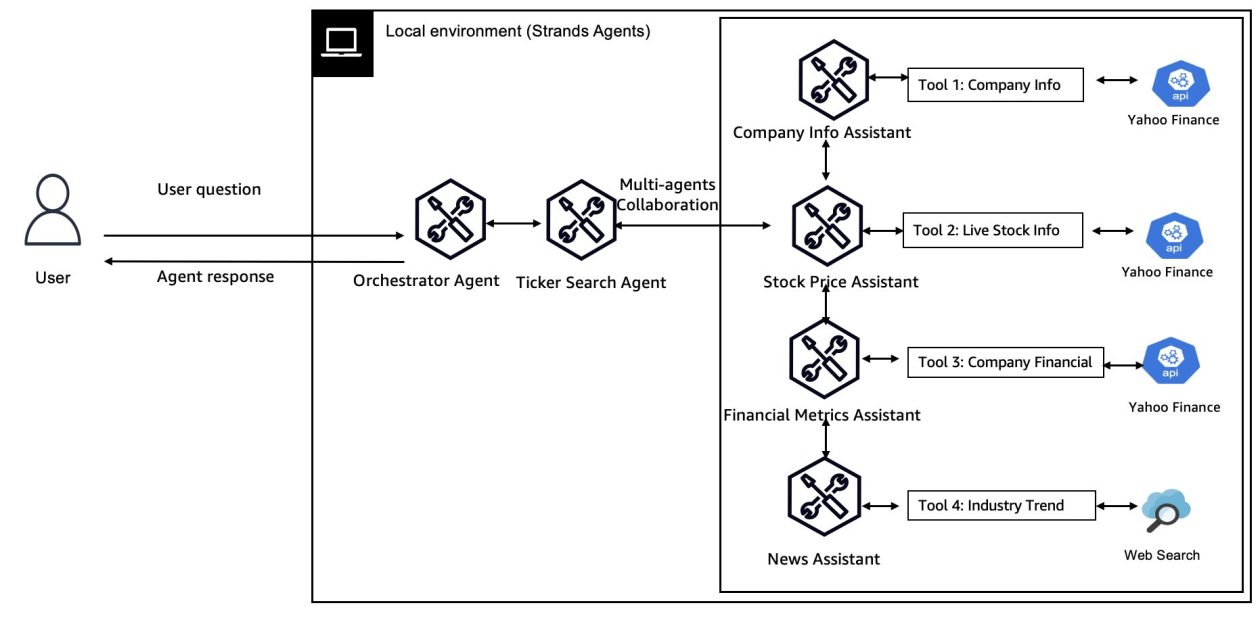








Amazon SageMaker AI를 활용한 AWQ와 GPTQ를 이용한 LLM 추론 가속화
본문에서는 양자화 모델이 Amazon SageMaker AI에 어떻게 원활하게 배포되는지 살펴봅니다. 양자화는 추론 비용을 낮추고 자원이 제한된 하드웨어에 배포를 지원하며, 현대 LLM의 금융 및 환경적 영향을 줄이면서 대부분의 성능을 유지하는 방법을 탐구합니다. PTQ의 원리에 대해 심층적으로 살펴보고 선택한 모델을 양자화하고 Amazon SageMaker에 배포하는 방법을 시연합니다.