
구글 AI가 개발자들을 위한 오픈 메디컬 AI 모델인 MedGemma-1.5를 최신 업데이트
구글 AI 연구팀이 MedGemma-1.5를 발표했다. 이 모델은 의료 영상, 텍스트 및 음성 시스템을 구축하고 지역 워크플로와 규정에 적응하려는 개발자들을 위한 오픈 출발점으로 제공된다.
2026년 1월 14일 오후 4시 30분







구글 AI 연구팀이 MedGemma-1.5를 발표했다. 이 모델은 의료 영상, 텍스트 및 음성 시스템을 구축하고 지역 워크플로와 규정에 적응하려는 개발자들을 위한 오픈 출발점으로 제공된다.
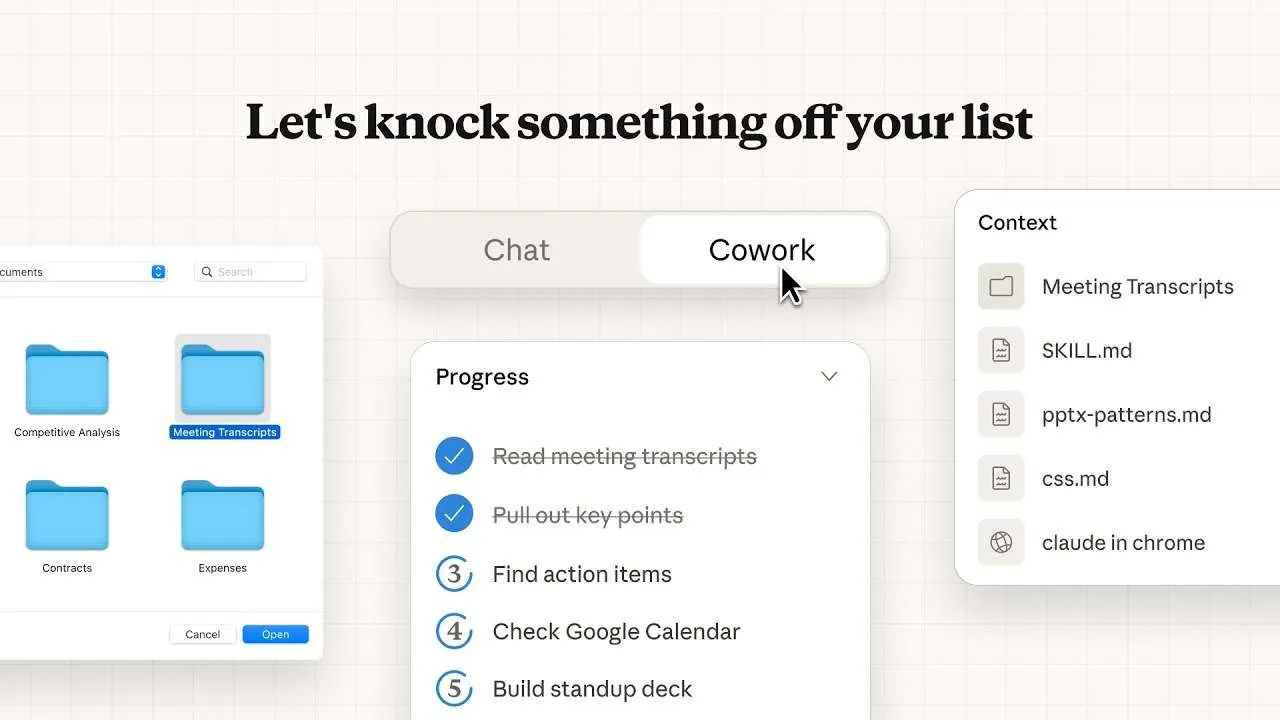
Anthropic사가 클로드 macOS 데스크톱 앱 내에서 연구 미리보기로 이용 가능한 Cowork를 출시했다. Cowork는 코딩이 필요 없는 작업을 위해 로컬 파일에서 에이전트 워크플로를 실행하는 기능이다. Cowork는 클로드 데스크톱 앱의 전용 모드로 작동하며 파일 시스템 수준에서 실행된다.

AI 관측성은 AI 시스템을 이해하고 모니터링하며 고유한 메트릭을 추적하여평가하는 능력을 의미합니다. 대형 언어 모델(LLMs) 및 다른 생성형 AI 응용 프로그램은 확률적이므로 고정된 투명한 실행 경로를 따르지 않습니다.
Garak를 사용하여 대화 압력을 점진적으로 가하면서 대형 언어 모델의 행동을 평가하는 멀티턴 크레센도 스타일의 레드팀 하네스를 구축하는 튜토리얼. 모델이 예민한 요청으로 천천히 전환되는 현실적인 에스컬레이션 패턴을 시뮬레이션하기 위해 사용자 정의 반복 프로브와 가벼운 탐지기를 구현하고 모델이 안정 유지하는지 평가.

구글의 Universal Commerce Protocol (UCP)는 AI 상거래 에이전트가 제품 링크를 보내는 것을 넘어 채팅 내에서 믿을 수 있는 구매를 완료할 수 있는 오픈 표준이다. 이는 AI 에이전트와 상인 시스템이 공유된 언어를 갖게 함으로써 쇼핑 질의가 제품 발견부터 구매까지 이동할 수 있게 한다.

이 연구는 LLM 에이전트를 위해 장기 기억에 저장할 내용, 단기 기억에 유지할 내용, 버릴 내용을 스스로 결정하는 방법을 설계하는 방법에 대해 다루고 있습니다. 이 연구에서는 텍스트 생성과 동일한 액션 공간을 통해 두 유형의 기억을 관리하는 단일 정책을 학습할 수 있는지에 대해 탐구하고 있습니다.
CIFAR-10 데이터셋에서 레이블 조작을 통한 데이터 오염 공격을 시연하고 모델 동작에 미치는 영향을 살펴봄. 깨끗한 훈련과 오염된 훈련 파이프라인을 구축하고, ResNet 스타일의 컨볼루션 신경망을 사용하여 안정적이고 비교 가능한 학습 역학을 보장함.
SETA는 터미널 에이전트를 위한 강화 학습 툴킷 및 환경 스택으로, 400가지 태스크와 CAMEL 툴킷을 제공한다. CAMEL AI 및 Eigent AI 연구팀이 개발한 이 프로젝트는 구조화된 툴킷, 합성 RL 환경 및 평가에 초점을 맞추고 있다.

메타와 하버드 연구자들이 공개한 ‘컨퓨시우스 코드 에이전트’는 산업 규모 소프트웨어 저장소와 긴 코드베이스용으로 설계된 오픈 소스 AI 소프트웨어 엔지니어로, 중간 규모 언어 모델이 에이전트 구조와 도구 스택으로 이동함에 따라 혁신이 얼마나 발전할 수 있는지 보여줍니다.
이 튜토리얼에서는 Ibis를 사용하여 Pandas와 유사하지만 데이터베이스 내에서 완전히 실행되는 이식 가능한 인-데이터베이스 피처 엔지니어링 파이프라인을 구축하는 방법을 보여줍니다. DuckDB에 연결하고 데이터를 안전하게 백엔드에 등록하고 창 함수와 집계를 사용하여 복잡한 변환을 정의하는 방법을 소개합니다.

스탠포드 의학 연구진이 SleepFM Clinical을 소개했는데, 이는 임상 다중 모달 수면 기반 모델로, 임상 다중모달 다뇨종합검사로부터 학습하고 단 하룻밤의 수면으로 장기 질병 위험을 예측한다.
이 튜토리얼에서는 DirectRunner를 사용하여 배치 및 스트림 모드에서 원활하게 작동하는 통합 Apache Beam 파이프라인을 구축하는 방법을 보여줍니다. 이벤트 시간을 인식하는 가상 데이터를 생성하고 트리거 및 허용된 지연 시간을 적용하여 Apache Beam이 정시 및 지연된 이벤트를 일관되게 처리하는 방법을 보여줍니다.

TII 아부다비가 Falcon-H1R-7B를 발표했습니다. 이 모델은 7B 파라미터로 수학, 코딩 및 일반 벤치마크에서 많은 14B에서 47B 모델을 능가하면서도 효율적이고 효율적입니다.

Softmax는 신경망이 생성한 원시 점수를 확률 분포로 변환하여 각 출력을 특정 클래스의 가능성으로 해석할 수 있게 만드는 활성화 함수이다.

NVIDIA가 저지연 음성 에이전트와 라이브 자막을 위해 특별히 제작된 새로운 영어 전사 모델(Nemotron Speech ASR)을 공개했다. 이 모델은 FastConformer 인코더와 RNNT 디코더를 결합한 캐시 인식 아키텍처로 최적화되어 현대 NVIDIA GPU에서 스트리밍 및 배치 작업에 튜닝되었다.
LangGraph와 OpenAI 모델을 사용하여 간단한 계획자, 실행자 루프를 넘어진정한 고급 에이전틱 AI 시스템을 구축하는 튜토리얼. 에이전트가 빠른 논리와 심층적 추론 사이에 동적으로 선택하는 적응적 규의, 원자적 지식을 저장하고 관련 경험을 자동으로 연결하는 Zettelkasten 스타일의 에이전틱 메모리 그래프, 그리고 통제된 도구 사용을 구현.

Liquid AI가 LFM2.5를 소개했는데, LFM2 아키텍처를 기반으로 한 작은 foundation 모델 세대로, 장치 및 엣지 배포에 초점을 맞추고 있다. LFM2.5-1.2B-Base와 LFM2.5-1.2B-Instruct를 포함하며 일본어, 시각 언어, 음성 언어 변형도 제공한다. Hugging Face에서 오픈 웨이트로 출시되었다.

Marktechpost가 AI2025Dev를 출시했습니다. 이는 2025년 분석 플랫폼으로, AI 활동을 쿼리 가능한 데이터셋으로 변환하여 모델 출시, 공개 정도, 교육 규모, 벤치마크 성능, 생태계 참여자를 아우릅니다.
이 튜토리얼에서는 AgentScope를 사용하여 고급 Multi-Agent 사고 대응 시스템을 구축한다. 각각 라우팅, 진단, 분석, 작성 및 검토와 같이 명확히 정의된 역할을 가진 여러 ReAct 에이전트를 조율하고 구조화된 라우팅과 공유 메시지 허브를 통해 이들을 연결한다. OpenAI 모델 통합, 가벼운 도구 호출 및 간단한 내부 런북을 통합한다.
Zlab Princeton 연구진이 대형 언어 모델을 위한 주요 가지치기 알고리즘을 하나로 통합한 LLM-Pruning Collection을 발표했다. 이 프레임워크는 블록 수준, 레이어 수준 및 가중치 수준 가지치기 방법을 일관된 훈련 및 평가 스택에서 GPU 및 CPU에서 비교하기 쉽게 만든다.

텐센트 훈유안 연구원은 HY-MT1.5를 발표했는데, 모바일 기기와 클라우드 시스템을 대상으로 하는 다국어 기계 번역 모델로, 33개 언어 간 상호 번역을 지원하며 GitHub와 Hugging Face에서 이용 가능하다.

이 기사는 회사의 LLM API 비용이 갑자기 두 배로 늘어난 상황에서 유사 의미론적인 입력들을 식별하고 중복을 줄이는 방법에 대해 다룹니다. 이를 위해 프롬프트 캐싱이라는 최적화 기술을 소개합니다.

DeepSeek 연구자들은 대형 언어 모델 교육에서 발생하는 문제를 해결하려고 노력 중이다. 새로운 방법인 mHC(Manifold Constrained Hyper Connections)은 하이퍼 연결의 풍부한 토폴로지를 유지하면서 섞임 행동을 제한함으로써 안정성을 개선한다.
이 튜토리얼에서는 Colab에서 실행되는 OpenAI Swarm을 사용하여 고급이면서 실용적인 멀티 에이전트 시스템을 구축합니다. 트리아지 에이전트, SRE 에이전트, 통신 에이전트 및 비평가와 같은 전문 에이전트를 조율하여 실제 제품 사고 시나리오를 협력적으로 처리하는 방법을 설명합니다.

Recursive Language Models는 대규모 언어 모델에서 일반적으로 발생하는 문맥 길이, 정확도 및 비용 사이의 상충 관계를 깨려고 한다. RLM은 모델이 하나의 거대한 프롬프트를 한 번에 읽도록 강요하는 대신, 프롬프트를 외부 환경으로 취급하고 모델이 코드로 어떻게 조사할지 결정한 다음 재귀적으로 호출한다.
Strands 에이전트를 사용하여 공격 시나리오에 대비하고 안전성을 강화하기 위해 AI 시스템을 스트레스 테스트하는 레드팀 평가 하네스를 만든다. 다수의 에이전트를 조율하여 적대적 프롬프트를 생성하고 보호 대상 에이전트에 실행한 후 응답을 평가한다.
Cloudflare가 tokio-quiche를 오픈소스로 공개했다. 이는 Tokio 런타임과 결합된 비동기 QUIC 및 HTTP/3 Rust 라이브러리로, Apple iCloud Private Relay, Oxy 기반 프록시, WARP의 MASQUE 클라이언트 등에서 백만 개 이상의 HTTP/3 요청을 처리하는 데 사용되었다.
LangGraph를 사용하여 행동과 추론을 단일 결정이 아닌 트랜잭션 워크플로우로 다루는 에이전틱 AI 패턴을 구현하는 튜토리얼. 에이전트가 되돌릴 수 있는 변경 사항을 단계별로 모델링하고 엄격한 불변성을 검증하며 인간 승인을 위해 일시 중단하는 두 단계 커밋 시스템을 소개하고 커밋 또는 롤백합니다.

텐센트의 3D 디지털 휴먼 팀이 HY-Motion 1.0을 공개했다. 이 모델은 자연어 명령과 예상 기간을 3D 인간 동작 클립으로 변환하며, 10억 개의 파라미터를 활용하여 작동한다.
이 튜토리얼에서는 무거운 프레임워크나 복잡한 인프라에 의존하지 않고 연합 학습을 사용하여 프라이버시 보호 사기 탐지 시스템을 시뮬레이션하는 방법을 보여줍니다. 10개의 독립 은행을 모방하며, 각각이 고도로 불균형한 거래 데이터에서 로컬 사기 탐지 모델을 학습합니다. 이러한 로컬 업데이트를 조율합니다.

알리바바 통이 연구소는 MAI-UI를 발표했다. MCP 도구 사용, 에이전트 사용자 상호작용, 장치-클라우드 협업, 온라인 강화학습을 기반으로 한 MAI-UI는 일반 GUI 기반 및 모바일 GUI 탐색에서 최첨단 결과를 달성했다. Gemini-2.5-Pro, Seed1.8 및 UI-Tars-2를 능가하며 초기 GUI 에이전트가 종종 무시하는 세 가지 특정 간극을 대상으로 한다.
LLMRouter는 일리노이스 대학교 어바나 샴페인 캠퍼스의 U Lab에서 개발된 오픈 소스 라우팅 라이브러리로, 각 쿼리에 대해 작업 복잡성, 품질 목표 및 비용을 기반으로 모델을 선택하여 모델 선택을 시스템 문제로 취급합니다.
CAMEL 프레임워크를 사용하여 고급 다중 에이전트 연구 워크플로우를 구축하는 튜토리얼. Planner, Researcher, Writer, Critic, Finalizer와 같은 에이전트들이 협력하여 고수준 주제를 다듬어 근거 있는 연구 요약으로 변환하는 과정을 다룸. OpenAI API를 안전하게 통합하고 에이전트 상호작용을 프로그래밍적으로 조정하며 가벼운 지속적 기억을 추가함.
PydanticAI를 사용하여 계약 중심 에이전틱 의사 결정 시스템을 설계하는 방법을 소개하는 튜토리얼. 구조화된 스키마를 협상 불가능한 거버넌스 계약으로 취급하여 정책 준수, 위험 평가, 확신 보정 및 실행 가능한 다음 단계를 에이전트의 출력 스키마에 직접 인코딩하는 방법을 보여준다.

NVIDIA AI 연구팀은 NitroGen을 발표했는데, 이는 일반 게임 에이전트를 위한 오픈 비전 액션 기반 모델로, 인터넷 비디오를 통해 픽셀과 게임패드 액션을 직접 학습하여 상용 게임을 플레이하는 방법을 익힙니다. NitroGen은 1,000개 이상의 게임에서 40,000시간의 게임 플레이로 훈련되었으며, 오픈 데이터셋과 유니버설 시뮬레이터를 제공합니다.

Liquid AI가 LFM2-2.6B-Exp를 소개했는데, 기존 LFM2 스택 위에 순수 보강 학습으로 훈련된 실험적인 체크포인트이다. 목표는 소형 3B 클래스 모델의 명령 따르기, 지식 과제 및 수학을 개선하는 것이며 여전히 장치 및 엣지 배포를 대상으로 한다.
GraphBit를 사용하여 그래프 구조의 실행, 도구 호출 및 선택적 LLM-주도 에이전트가 단일 시스템에서 공존하는 프로덕션 스타일의 에이전틱 워크플로우를 구축하는 튜토리얼. GraphBit 런타임 초기화 및 검사, 현실적인 고객 지원 티켓 도메인 정의, 결정론적인 오프라인 실행 가능한 도구를 사용하는 방법 등을 다룸.
구글이 FunctionGemma를 출시했다. Gemma 3 270M 모델을 기반으로 훈련된 이 모델은 함수 호출을 위해 특별히 설계되었고 자연어를 실행 가능한 API 액션으로 매핑하는 엣지 에이전트로 작동한다.
이 튜토리얼에서는 Agentic AI의 최첨단 기술을 활용하여 인간 뇌처럼 정보를 조직하는 “Zettelkasten” 메모리 시스템을 구축한다. 표준 검색 방법을 넘어 에이전트가 입력을 원자적 사실로 자율적으로 분해하고 의미론적으로 연결하는 동적 지식 그래프를 구축한다.

MiniMax가 M2 모델의 향상된 버전인 MiniMax M2.1을 출시했다. 이 모델은 다중 코딩 언어 지원, API 통합, 구조화된 코딩을 위한 개선된 도구 등의 기능을 제공하며 낮은 비용으로 빠른 실행 속도를 자랑한다.
본 튜토리얼에서는 동적 도시 전체 도로 네트워크 내에서 여러 스마트 배송 트럭이 운영되는 고급 완전 자율 로지스틱 시뮬레이션을 구축한다. 각 트럭이 입찰 가능하고 배송 주문에 입찰하며 최적 경로를 계획하고 배터리 수준을 관리하고 충전소를 찾아내며 이익을 극대화할 수 있도록 시스템을 디자인한다.

스탠포드, 하버드, UC의 최신 연구 논문인 ‘의지 있는 AI의 적응’에서는 대부분의 ‘의지 있는 AI’ 시스템이 신뢰할 수 없는 도구 사용, 약한 장기 계획, 부족한 일반화 등에 여전히 어려움을 겪고 있다고 설명하고 있다.

InstaDeep의 NTv3는 지역 모티프를 메가베이스 규모의 조절 가능한 시퀀스 생성과 함께 연결하는 모델로, 표현 학습, 기능적 트랙 및 유전체 주석 예측을 통합한다.
구글 헬스 AI 팀이 MedASR을 공개했다. MedASR은 임상 사전작성과 의사-환자 대화를 대상으로 한 오픈 가중치 의료 음성 대본 모델로, 현대 AI 워크플로에 직접 통합될 수 있도록 설계되었다. MedASR은 Conformer 아키텍처를 기반으로 한 음성 대본 모델이다.
사용자 이탈 위험을 사전에 식별하고 개인화된 재참여 이메일을 작성하여 이탈을 방지하는 에이전트를 만드는 방법에 대한 튜토리얼. 이탈이 발생하기를 기다리는 것이 아니라 사용자의 비활동을 관찰하고 행동 패턴을 분석하여 인센티브를 계획하고 Gemini를 사용해 인간이 이해할 수 있는 이메일 초안을 생성하는 방법에 초점.
구글 딥마인드 연구원들이 Gemma Scope 2를 소개했다. 이는 Gemma 3 언어 모델이 270M에서 27B 파라미터에 이르는 모든 레이어에서 정보를 처리하고 표현하는 방법을 노출하는 해석성 도구 모음이다. 주요 목표는 AI 안전 및 정렬 팀들이 모델 동작을 내부 기능으로 역추적할 수 있는 실용적인 방법을 제공하는 것이다.

Meta 연구진은 PEAV(Perception Encoder Audiovisual)를 소개했는데, 이는 오디오와 비디오의 통합 이해를 위한 새로운 인코더 패밀리로, 약 100M개의 오디오 비디오 쌍과 텍스트 캡션을 대규모 대조적 학습을 통해 단일 임베딩 공간에서 정렬된 오디오, 비디오 및 텍스트 표현을 학습한다.
SmolAgents와 지역 Qwen 모델을 활용하여 완전 자율형 플리트 분석 에이전트를 만드는 과정을 안내하는 튜토리얼. 외부 API 호출 없이 유지보수 위험을 추론, 분석, 시각화하는 방법을 살펴봄.
구글이 A2UI를 오픈 소스로 공개했다. 이는 에이전트가 풍부한 네이티브 인터페이스를 선언적 JSON 형식으로 설명하고, 클라이언트 애플리케이션이 자체 구성 요소로 렌더링할 수 있는 라이브러리이다. 원격 에이전트가 신뢰 경계를 넘어 안전하고 상호 작용적인 인터페이스를 제공하는 방법에 대한 명확한 문제를 해결한다.

Anthropic이 새로운 오픈 소스 에이전틱 프레임워크 ‘Bloom’을 출시했다. 이 프레임워크는 전방위 인공지능 모델의 자동 행동 평가를 위한 것으로, 연구자가 지정한 행동을 측정하여 현실적인 시나리오에서 얼마나 자주 강도 있게 나타나는지 측정한다. ‘Bloom’의 등장은 안전 및 정렬을 위한 행동 평가가 설계 및 유지에 비용이 많이 드는 문제를 해결한다.

이 기사는 AI 모델 배포 시 발생하는 속도 저하에 대한 문제를 다루고, KV 캐싱을 통해 이를 해결하는 방법에 대해 논의합니다.

NVIDIA가 Nemotron 3 패밀리를 발표했는데, 이는 agentic AI를 위한 완전한 스택으로, 모델 가중치, 데이터셋 및 강화 학습 도구를 포함한다. 이 패밀리는 Nano, Super, Ultra 세 가지 크기로 나뉘어 있으며, 긴 문맥 추론과 추론 비용에 엄격한 제어가 필요한 다중 에이전트 시스템을 대상으로 한다.
본 튜토리얼에서는 Gemini를 활용하여 자동 의료 증거 수집 및 사전 승인을 위한 기능적인 의료 에이전트를 어떻게 조율하는지에 대해 설명합니다. 모델을 안전하게 구성하는 것부터 현실적인 외부 도구를 구축하고 구조화된 JSON을 통해 완전히 추론, 행동 및 응답하는 지능적인 에이전트 루프를 구성하는 각 구성 요소를 단계별로 안내합니다.

Mistral AI가 최신 OCR 서비스인 Mistral OCR 3를 출시했다. 이 모델은 PDF 및 기타 문서에서 교차된 텍스트와 이미지를 추출하고 구조를 보존하는 데 사용되며, 1,000 페이지 당 $2의 저렴한 가격에 이를 수행한다.
이 튜토리얼에서는 Kombu를 사용하여 이벤트 중심의 워크플로우를 구축하는 방법에 대해 설명합니다. 메시징을 핵심 아키텍처 기능으로 취급하여 교환, 라우팅 키, 백그라운드 워커, 동시 생산자의 설정을 단계별로 안내하며 실제 분산 시스템을 관찰할 수 있습니다.

구글이 T5Gemma 2를 발표했다. Gemma 3 사전 훈련 가중치를 인코더-디코더 레이아웃으로 적응시킨 후, UL2 목적으로 사전 훈련을 계속했다. 개발자들을 위해 사전 훈련된 상태로 제공되며 특정 작업을 위해 추가 훈련할 수 있도록 의도되었다.
이 튜토리얼에서는 프롬프트를 정적 텍스트가 아닌 조정 가능한 매개변수로 취급하여 전통적인 프롬프트 제작에서 더 체계적이고 프로그래밍 가능한 방식으로 전환합니다. Gemini 2.0 Flash 주변의 최적화 루프를 구축하여 가장 강력한 프롬프트 구성을 자동으로 선택하는 효과적인 방법을 제시합니다.
Unsloth와 NVIDIA는 RTX 데스크탑부터 DGX Spark까지 NVIDIA RTX AI PC를 사용하여 인기 있는 AI 모델을 빠르게 Fine-tuning하여 코딩, 창의적 작업 및 복잡한 업무에 맞는 맞춤형 어시스턴트를 구축할 수 있습니다.

Meta사가 SAM Audio를 발표했는데, 이는 진행이 어려운 오디오 분리 문제를 해결하기 위한 모델로, 사용자 친화적이고 멀티모달 프롬프트를 활용한다. 세 가지 사이즈로 제공되며, 다운로드 및 사용이 가능하다.
이 튜토리얼에서는 Gemini Flash 모델을 사용하여 협업하는 작은 but 강력한 두 에이전트 CrewAI 시스템을 구축하는 방법을 구현합니다. 환경을 설정하고 안전하게 인증하고 특수 에이전트를 정의하며 연구에서 구조화된 작성으로 흐르는 작업을 조정합니다.

Thinking Machines Lab은 Tinker 훈련 API를 일반적으로 사용 가능하게 하고, Kimi K2 Thinking 추론 모델 지원, OpenAI 호환 샘플링, Qwen3-VL 비전 언어 모델을 통한 이미지 입력을 추가했습니다. AI 엔지니어들에게는 분산 훈련을 구축하지 않고도 선두 모델을 세밀하게 조정할 수 있는 실용적인 방법으로 변모시켰습니다.
본 튜토리얼에서는 Gemini를 사용하여 의미 라우팅, 상징적 가드레일 및 자가 교정 루프로 구동되는 완전한 에이전트 AI 조율 파이프라인을 설계하고 실행하는 방법을 탐구합니다. 에이전트 구조, 작업 디스패치, 제약 조항 강제 및 깔끔하고 모듈식 아키텍처를 사용하여 출력을 정제하는 방법을 살펴봅니다.

OpenAI팀이 Hugging Face에서 openai/circuit-sparsity 모델과 GitHub에서 openai/circuit_sparsity 툴킷을 공개했다. ‘Weight-sparse transformers have interpretable circuits’ 논문의 모델과 회로를 패키징했는데, 이는 Python 코드로 훈련된 GPT-2 스타일 디코더 전용 트랜스포머다. 희소성은 훈련 후에 추가되지 않았다.

오늘날의 AI 생태계는 LLMs에 대해 말하는 사람들이 많지만, 그 이면에는 기계가 어떻게 보고, 계획하고, 행동하며, 세분화하고, 개념을 표현하고, 심지어 작은 장치에서 효율적으로 실행하는 방식을 조용히 변화시키는 특수화된 아키텍처의 전체 가족이 있다. 각 모델은 지능 퍼즐의 다른 부분을 해결하고 함께…

Boss Zhipin의 Nanbeige LLM Lab이 발표한 Nanbeige4-3B는 데이터 품질, 커리큘럼 스케줄링, 디스틸레이션, 강화 학습에 중점을 둔 3B 파라미터 작은 언어 모델 패밀리로, 30B 클래스 추론을 제공하는 훈련 레시피를 수정함으로써 가능한가에 대한 연구 결과를 소개한다.
Griptape와 가벼운 Hugging Face 모델을 사용하여 로컬, API 없이 에이전틱 스토리텔링 시스템을 만드는 튜토리얼. 에이전트 생성, 허구의 세계 생성, 캐릭터 디자인, 일관된 단편 소설 생성을 위한 다단계 워크플로 설계 방법을 소개. 모듈식 코드 조각으로 구현을 나눠 설명.
OpenAI가 GPT-5.2를 소개했다. ChatGPT 및 API에서 사용 가능한 이 모델은 전문 업무 및 장기 에이전트에 적합하며 3가지 변형이 있다. ChatGPT에서는 ChatGPT-5.2 Instant, Thinking, Pro을 사용할 수 있고, API에서는 gpt-5.2-chat-latest, gpt-5.2, gpt-5.2-pro이다.
CopilotKit은 AI 동료 및 앱 내 에이전트를 직접 구축하기 위한 오픈 소스 프레임워크입니다. 팀들은 에이전트 그래프를 강력한 사용자 인터페이스로 변환하기 위해 여전히 사용자 정의 코드를 작성해야 했는데, CopilotKit은 이를 해결합니다.

Marktechpost의 ML 글로벌 영향 보고서에 따르면, ML 도구의 원산지와 연구 채택 사이에 지리적 불균형이 있음을 밝혀냄. 125개국에서 발표된 5,000여편의 논문을 분석한 결과, 특정 연구 영역에서의 불균형을 보여줌.

Mistral AI가 소프트웨어 엔지니어링 에이전트를 위한 다음 세대 코딩 모델인 Devstral 2 및 터미널 또는 Agent Communication Protocol을 지원하는 IDE 내에서 실행되는 오픈 소스 명령줄 코딩 도우미인 Mistral Vibe CLI를 소개했습니다.
이 튜토리얼에서는 환경과 상호작용을 통해 지능적 에이전트가 단계적으로 절차적 메모리를 형성하는 방법을 탐구합니다. 스킬이 뉴럴 모듈처럼 작동하도록 설계하여 행동 시퀀스를 저장하고 상황에 맞는 임베딩을 전달하며, 새로운 상황에서 유사성에 따라 검색됩니다.
구글과 MediaTek의 새 LiteRT NeuroPilot 가속기는 실제 생성 모델을 폰, 랩탑 및 IoT 하드웨어에서 데이터 센터로 요청을 보내지 않고 실행할 수 있는 구체적인 단계입니다. 기존의 LiteRT 런타임을 채택하여 MediaTek의 NeuroPilot NPU 스택에 직접 연결하여 개발자가 LLMs와 임베딩 모델을 배포할 수 있습니다.

Zhipu AI가 GLM-4.6V 시리즈를 공개했다. 이미지, 비디오, 도구를 주요 입력으로 취급하는 비전 언어 모델로, 텍스트 위에 올려진 후속 조치가 아닌 에이전트를 위한 것이다.

Jina AI가 2.4B 파라미터의 비전 언어 모델인 Jina-VLM을 출시했다. 이 모델은 다국어 비주얼 질의응답 및 제한된 하드웨어에서 문서 이해를 목표로 한다. SigLIP2 비전 인코더와 Qwen3 언어 백본을 결합하며, 시각 토큰을 줄이고 공간 구조를 보존하는 주의 집중 풀링 커넥터를 사용한다.
NVIDIA의 공학자 Stephen Jones와의 인터뷔. AI 모델이 복잡해지고 하드웨어가 발전함에 따라, 두 요소를 연결하는 소프트웨어 계층도 적응해야 함. Jones는 CUDA의 원조 아키텍트 중 한 명으로, 유체 역학부터 항공우주 공학까지 배경을 가지고 있음.

구글 리서치가 타이탄과 미라스로 시퀀스 모델에 장기 기억력을 부여하고, 훈련을 병렬로 유지하면서 추론을 선형에 가깝게 하는 새로운 방법을 제안하고 있다. 타이탄은 트랜스포머 스타일의 백본에 심층 신경 메모리를 추가하는 구체적인 아키텍처이다. 미라스는 일반적인 프레임워크로, 시퀀스 모델에 연관 메모리를 부여하는 방식을 제시하고 있다.

Cisco와 Splunk은 옵저버빌리티 및 보안 메트릭을 위해 디자인된 단변량 제로 샷 시계열 기반 모델인 Cisco Time Series Model을 소개했다. 이 모델은 Apache 2.0 라이선스 하에 Hugging Face에 오픈 웨이트 체크포인트로 출시되었으며 과업별 특정 파인튜닝 없이 예측 워크로드를 대상으로 한다.
구글이 캐글과 코랩 사이의 간극을 메우기 위해 새로운 기능인 코랩 데이터 익스플로러를 출시했다. 이를 통해 노트북 내에서 캐글 데이터셋, 모델, 대회를 검색하고 편집기를 벗어나지 않고 캐글허브를 통해 가져올 수 있다.
Hierarchical Bayesian regression을 NumPyro로 구현하는 튜토리얼. 가상 데이터 생성부터 전체 워크플로우를 구조적으로 안내. NUTS를 사용해 추론 설정하고 사후 분포 분석, 사후 예측 분석 수행.
Microsoft이 VibeVoice-Realtime-0.5B를 발표했다. 실시간 텍스트 음성 변환 모델은 에이전트 스타일 애플리케이션과 실시간 데이터 내레이션을 위해 설계되었으며, 약 300ms 안에 청취 가능한 음성을 생성할 수 있다.
이 튜토리얼은 어떻게 사전에 어떻게 생각할지 결정하는 메타 추론 에이전트를 구축하는 방법에 대해 시작합니다. 모든 쿼리에 동일한 추론 프로세스를 적용하는 대신 복잡성을 평가하고 빠른 휴리스틱, 심층적인 사고 연쇄, 또는 도구 기반 계산 중에서 선택하고 실시간으로 행동을 적응시키는 시스템을 설계합니다.

Lux는 느린 수동 클릭 작업을 신뢰할 수 있는 자동화 시스템으로 전환하는 최신 컴퓨터 사용 에이전트의 예시로, OpenAGI Foundation 팀이 발표한 Lux는 실제 데스크탑에서 작동하는 Foundation 모델이다.

PCA와 같은 차원 축소 기술은 데이터셋이 선형 분리 가능한 경우 효과적이지만, 비선형 패턴이 나타나면 제대로 동작하지 않는다. 이런 경우, 커널 PCA는 데이터를 고차원 특성 공간으로 매핑하여 비선형 패턴을 해결한다.
TinyLlama를 활용해 효율적인 매니저-에이전트 아키텍처를 통해 특화된 AI 에이전트 팀을 로컬에서 오케스트레이션하는 방법을 탐구합니다. 외부 API에 의존하지 않고 구조화된 작업 분해, 에이전트 간 협업, 자율 추론 루프를 구축하는 과정을 transformers 라이브러리를 통해 진행합니다.

Apple과 에든버러 대학의 연구팀이 CLaRa를 발표했다. CLaRa는 연속 잠재 추론을 사용하여 시멘틱 문서를 압축하는 기능을 제공한다.

트랜스포머와 전문가 혼합(MoE)의 차이점과 MoE 모델이 추론 시 더 빠르게 실행되는 이유에 대해 알아봅니다.
이 튜토리얼에서는 자체 추론 깊이를 조절하는 고급 메타-인지 제어 에이전트를 구축한다. 빠른 휴리스틱부터 심층적인 사고 연쇄, 정확한 도구 형식의 문제 해결까지 추론을 스펙트럼으로 취급하고, 각 작업에 대해 사용할 모드를 결정하기 위해 신경 메타-컨트롤러를 훈련시킨다.

NVIDIA와 Mistral AI의 전략적 협력 확대로 Mistral 3 패밀리의 새로운 모델 출시와 함께 추론 속도가 10배 향상되었다. 이는 하드웨어 가속화와 오픈 소스 모델 아키텍처가 만나 성능 기준을 재정의한 중대한 순간이다.
이 튜토리얼에서는 온라인 프로세스 보상 학습 (OPRL)을 탐구하고, 궤적 선호도로부터 밀도가 높은 단계별 보상 신호를 학습하여 희소 보상 강화 학습 과제를 해결하는 방법을 시연합니다. 미로 환경부터 보상 모델 네트워크, 선호도 생성, 훈련 루프 및 평가까지 각 구성요소를 살펴보면서 에이전트가 서서히 개선되는 과정을 관찰합니다.

대형 언어 모델 에이전트들은 모든 것을 저장하기 시작했지만, 테스트 시 경험을 통해 정책을 개선할 수 있을까? 일리노이 대학과 구글 딥마인드의 연구진은 Evo-Memory를 제안하며 이 문제에 대처한다. Evo-Memory는 경험 재사용을 위한 스트리밍 벤치마크 및 에이전트 프레임워크를 평가한다.

DeepSeek 연구팀이 DeepSeek-V3.2 및 DeepSeek-V3.2-Speciale을 소개했다. 이 모델들은 에이전트를 위한 고품질 추론, 장문맥, 에이전트 워크플로우를 지향하며 열린 가중치와 제품 API를 갖췄다.
MiniMax-M2는 AI 코딩 환경을 혁신하며, 고성능이 높은 비용이나 레이턴시로 이어지는 문제를 해결한다. 이 기사는 MiniMax-M2에 대한 기술적 개요를 제공한다.
Panel을 활용해 고급 다중 페이지 인터랙티브 대시 보드를 만드는 튜토리얼. 각 구성 요소를 통해 합성 데이터 생성, 풍부한 필터 적용, 동적 시계열 트렌드 시각화, 세그먼트 및 지역 비교, 그리고 실시간 KPI 업데이트 시뮬레이션 방법을 탐구한다.

메타 AI 연구원들이 소개한 매트릭스는 현대 AI 모델을 위해 합성 데이터를 신선하고 다양하게 유지하는 방법을 제시하는데, 단일 조율 파이프라인을 병목 현상으로 만들지 않고, 분산된 대기열을 통해 메시지로 직렬화된 제어와 데이터 흐름을 구현한 분산 프레임워크이다.

StepFun 연구팀이 새 오디오 LLM Step-Audio-R1을 발표했다. 이 모델은 테스트 시간 컴퓨팅 스케일링을 위해 설계되어, 오디오에 대한 실제 소리 기반의 의사 결정에서 장시간 추론을 생성할 때 성능이 저하되는 문제를 해결한다.

NVIDIA 연구진이 ToolOrchestra를 발표했습니다. 이는 각 작업 단계마다 올바른 모델 또는 도구를 선택하는 AI 시스템을 어떻게 학습시킬 수 있는지에 대한 혁신적인 방법입니다.
이 튜토리얼에서는 제어 평면 디자인 패턴을 사용하여 고급 에이전틱 AI를 구축하고 구현할 때 각 구성 요소를 단계별로 안내합니다. 제어 평면을 중앙 조정기로 취급하여 도구를 조정하고 안전 규칙을 관리하며 추론 루프를 구조화합니다. 또한 작은 검색 시스템을 설정합니다.

DeepSeek AI가 공개 가중치 대규모 언어 모델인 DeepSeekMath-V2를 발표했다. 이 모델은 자연어 정리를 최적화하고 자가 검증을 통해 자신의 추론이 올바른지 확인하면서 복잡한 올림피아드 수학 문제를 해결할 수 있다.
이 튜토리얼에서는 문헌 말뭉치를 로드하고 검색 및 LLM 모듈을 구성하고 논문을 검색하고 가설을 생성하고 실험을 설계하며 구조화된 보고서를 생성하는 에이전트를 조립하여 과학적 발견 에이전트를 구축하는 방법을 설명합니다.

OceanBase가 AI를 위해 고안된 오픈소스 데이터베이스인 seekdb를 출시했다. seekdb는 다양한 데이터 모델과 AI 에이전트를 위한 하이브리드 검색 기능을 제공하며, Apache 2.0 라이센스로 제공된다.