
앤트로픽, 클로드 오퍼스 4.7 출시: 에이전틱 코딩 및 고해상도 비전 향상
앤트로픽이 클로드 오퍼스 4.7을 출시했습니다. 이번 버전은 에이전틱 소프트웨어 엔지니어링과 멀티모달 기능에서 중요한 개선을 이루었으며, 실제 AI 애플리케이션 개발에 큰 도움이 될 것으로 기대됩니다.
2026년 4월 18일 오후 5시 40분








앤트로픽이 클로드 오퍼스 4.7을 출시했습니다. 이번 버전은 에이전틱 소프트웨어 엔지니어링과 멀티모달 기능에서 중요한 개선을 이루었으며, 실제 AI 애플리케이션 개발에 큰 도움이 될 것으로 기대됩니다.

구글이 LLM 기반의 자동 진단 도구인 ‘Auto-Diagnose’를 발표했다. 이 도구는 통합 테스트 로그를 자동으로 분석하여 오류를 찾아내는 기능을 제공한다.
생성형 AI의 발전과 함께 보안 위협도 증가하고 있습니다. 2026년 가이드에서는 Mindgard, Garak, Microsoft의 PyRIT 등 19개의 주요 도구를 소개하며, 보안 팀이 데이터 유출 및 편향과 같은 취약점을 사전에 식별할 수 있도록 돕습니다.
OpenAI가 생명과학 분야에 진출하며, 약물 발견과 유전체 연구를 가속화하기 위해 GPT-Rosalind라는 AI 모델을 출시했습니다. 이 모델은 10-15년의 약물 발견 기간을 단축할 것으로 기대됩니다.

UCSD와 Together AI 연구팀이 파르카에(Parcae)라는 새로운 언어 모델 아키텍처를 소개했습니다. 이 모델은 기존 트랜스포머 모델의 두 배 크기와 같은 품질을 제공하면서도 효율성을 높였습니다.
인플렉션이 NVIDIA 아이징 디코딩 AI 모델을 자사의 스퀄(Sqale) 중성 원자 양자 컴퓨팅 플랫폼에 통합했다고 발표했다. 이번 협업은 양자 오류 수정의 속도 문제를 해결하기 위한 것이다.

타이니피쉬가 AI 에이전트를 위한 통합 웹 인프라 플랫폼을 출시했습니다. 이 플랫폼은 검색, 데이터 수집, 브라우저 자동화 기능을 하나의 API 키로 제공합니다.

NVIDIA와 메릴랜드 대학교 연구팀이 오디오 언어 모델 ‘AF-Next’를 공개했습니다. 이 모델은 음성, 환경 소음, 음악 등을 이해하는 데 강력한 성능을 발휘합니다.

메타 AI와 킹 압둘라 과학기술대학교(KAUST) 연구진이 신경망이 직접 컴퓨터 역할을 하는 신경 컴퓨터(NC)를 제안했다. 이 연구는 이론적 틀과 함께 두 가지 모델을 소개한다.
MiniMax가 자가 진화 에이전트 모델인 MiniMax M2.7을 오픈 소스로 공개했습니다. 이 모델은 SWE-Pro에서 56.22%, Terminal Bench 2에서 57.0%의 성과를 기록했습니다.

MIT, NVIDIA, 저장대학교 연구팀이 긴 체인 추론을 위한 KV 캐시 압축 방법인 TriAttention을 제안했습니다. 이 방법은 전체 주의 메커니즘과 동일한 성능을 유지하면서도 2.5배 더 높은 처리량을 자랑합니다.
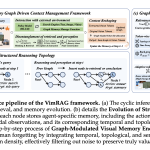
알리바바의 Tongyi Lab이 비주얼 데이터를 효과적으로 탐색할 수 있는 다중 모달 RAG 프레임워크인 VimRAG를 발표했습니다. 이 프레임워크는 메모리 그래프를 활용하여 대규모 시각적 맥락을 탐색하는 데 중점을 두고 있습니다.
NVIDIA가 PyTorch 모델에 최적의 추론 백엔드를 자동으로 찾아주는 오픈소스 툴킷 AITune을 출시했다. 이 툴킷은 연구자가 훈련한 모델과 실제 운영 환경에서 효율적으로 작동하는 모델 간의 간극을 줄이는 데 도움을 준다.
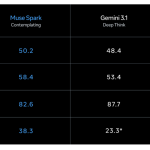
메타 슈퍼인텔리전스 연구소가 ‘뮤즈 스파크’를 발표했습니다. 이 모델은 도구 사용, 시각적 사고 과정, 다중 에이전트 조정을 지원하는 멀티모달 추론 모델입니다.
호라이즌 퀀텀 홀딩스가 아이온큐와 256큐비트 트랩드 이온 시스템 구매를 위한 전략적 협약을 체결했습니다. 이번 인수는 호라이즌 퀀텀의 하드웨어 테스트베드를 확장하기 위한 핵심 요소입니다.

딥 뉴럴 네트워크는 입력 공간을 재형성하여 복잡한 결정 경계를 형성하는 기하학적 시스템으로 이해될 수 있다. 이 과정에서 각 레이어는 의미 있는 공간 정보를 보존해야 한다.

구글 AI 연구팀이 연구 논문 작성을 자동화하는 다중 에이전트 프레임워크인 PaperOrchestra를 소개했다. 이 시스템은 연구자들이 실험 결과를 정리하고 논문을 작성하는 과정을 간소화하는 데 도움을 줄 것으로 기대된다.

AI 에이전트가 컴퓨터를 실제로 사용할 수 있도록 훈련하는 것은 현대 AI의 가장 어려운 인프라 문제 중 하나입니다. OSGym은 이러한 문제를 해결하기 위한 새로운 OS 인프라 프레임워크입니다.
Z.AI가 차세대 모델 GLM-5.1을 출시했습니다. 이 모델은 754억 개의 파라미터를 가진 에이전틱 모델로, SWE-Bench Pro에서 최첨단 성능을 달성하며 8시간의 자율 실행을 지원합니다.
IQM 양자 컴퓨터가 폴란드의 Galaxy Systemy Informatyczne와 54큐비트 시스템 공급 계약을 체결했다. 이 시스템은 2026년 4분기에 설치될 예정이다.

메타 AI가 1억 미만의 파라미터를 가진 새로운 비전 인코더 EUPE를 출시했습니다. 이 모델은 이미지 이해, 밀집 예측 및 언어-비전 모델 작업에서 전문 모델과 경쟁할 수 있는 성능을 자랑합니다.
IQM 양자 컴퓨터가 프라운호퍼 FOKUS와 협력하여 Eclipse Qrisp 프레임워크의 주요 업데이트를 발표했습니다. 이번 업데이트로 2048비트 키를 사용하는 쇼어 알고리즘의 첫 번째 전체 게이트 수준 컴파일에 성공했습니다.

MaxToki는 세포의 노화를 예측하고 그에 대한 대처 방법을 제시하는 인공지능입니다. 기존 생물학 모델의 한계를 극복하고 세포의 현재 상태를 분석하는 데 도움을 줍니다.

‘AutoAgent’는 AI 엔지니어가 자신의 에이전트를 최적화할 수 있도록 돕는 오픈소스 라이브러리입니다. 반복적인 작업을 줄이고 효율성을 높이는 데 기여할 것으로 기대됩니다.
패션은 항상 사람의 선호를 예측하는 것이며, 오늘날 인공지능을 통해 이러한 예측이 가능해졌다. 알고리즘과 머신러닝을 활용하여 패션의 미래를 디자인하는 방법을 살펴본다.
이 튜토리얼에서는 Z.AI의 GLM-5 모델을 활용하여 실제 에이전틱 애플리케이션을 위한 시스템 구축 방법을 소개합니다. 기본 환경 설정부터 고급 기능까지 단계별로 설명합니다.

기술 혁신 연구소(TII)가 자연어 프롬프트를 활용한 오픈 어휘 그라운딩 및 세분화를 위한 0.6B 매개변수 초기 융합 변환기 ‘Falcon Perception’을 발표했다. 이 기술은 언어와 비전 간의 상호작용을 개선할 것으로 기대된다.

Arcee AI가 복잡한 다단계 추론이 가능한 오픈 소스 AI 모델 ‘Trinity Large Thinking’을 Apache 2.0 라이선스 하에 공개했다. 이는 개발자들에게 투명한 대안을 제공한다.

IBM이 기업급 문서 데이터 추출을 위해 설계된 비전-언어 모델인 Granite 4.0 3B 비전을 출시했습니다. 이 모델은 고충실도의 시각적 추론을 제공하는 전문 어댑터로 구성되어 있습니다.

Z.ai가 GLM-5V-Turbo를 출시했습니다. 이 모델은 시각적 인식과 코드 실행 간의 간극을 메우는 데 중점을 두고 있으며, 소프트웨어 엔지니어링에 필요한 엄격한 구문으로 시각 정보를 변환하는 데 강점을 보입니다.
Hugging Face가 TRL(Transformer Reinforcement Learning) v1.0을 공식 출시했습니다. 이 버전은 연구 중심의 라이브러리에서 안정적인 프로덕션 준비 프레임워크로의 전환을 의미합니다.

구글이 비디오 생성 포트폴리오의 새로운 모델인 Veo 3.1 Lite를 발표했다. 이 모델은 생산 규모 배포의 주요 장애물인 가격 문제를 해결하기 위해 설계되었다.

Liquid AI가 LFM2.5-350M 모델을 출시했습니다. 이 모델은 28T 토큰으로 훈련된 350M 파라미터의 컴팩트한 구조로, 기존의 스케일링 법칙에 도전하는 사례로 주목받고 있습니다.

알리바바 Qwen 팀이 Qwen3.5-Omni를 출시했습니다. 이 모델은 텍스트, 오디오, 비디오를 통합하여 실시간 상호작용을 지원하는 멀티모달 언어 모델로, 기존의 모델들과 차별화된 점이 있습니다.

에이전트 인프라가 AI 에이전트를 위한 올인원 런타임인 AIO 샌드박스를 공개했습니다. 이 오픈소스 프로젝트는 코드 실행을 위한 기능적이고 격리된 환경을 제공합니다.

아마존 연구팀이 자율 AI 에이전트 개발을 자동화하는 A-Evolve라는 인프라를 발표했습니다. 이 프레임워크는 수동 조정 대신 자동화된 진화 과정을 통해 에이전트 개발을 혁신할 것으로 기대됩니다.

Chroma가 다중 홉 검색, 컨텍스트 관리 및 확장 가능한 합성 작업 생성을 위한 20억 파라미터의 에이전틱 검색 모델 ‘Context-1’을 발표했다. 이 모델은 기존의 컨텍스트 윈도우의 한계를 극복하는 데 중점을 두고 있다.

NVIDIA 연구진이 다중 턴 LLM 에이전트를 위한 강화 학습 인프라인 ProRL AGENT를 소개했다. 이 시스템은 ‘롤아웃-서비스’ 철학을 채택하여 에이전트 롤아웃 조정을 훈련 루프와 분리한다.

메타가 새로운 뇌 인코딩 모델 TRIBE v2를 발표했습니다. 이 모델은 비디오, 오디오, 텍스트 자극에 대한 fMRI 반응을 예측할 수 있는 기능을 갖추고 있습니다.

구글이 개발자들을 위해 ‘제미니 3.1 플래시 라이브’를 공개했습니다. 이 모델은 저지연의 자연스러운 음성 상호작용을 목표로 하며, 멀티모달 스트림을 처리할 수 있는 기술적 기반을 제공합니다.
NVIDIA가 새로운 AI 프레임워크인 PivotRL을 소개했습니다. 이 프레임워크는 4배 적은 롤아웃 턴으로 높은 에이전틱 정확도를 달성할 수 있도록 설계되었습니다.
구글이 대형 언어 모델의 메모리 통신 오버헤드를 줄이기 위해 TurboQuant라는 새로운 압축 알고리즘을 발표했습니다. 이 알고리즘은 LLM의 키-값 캐시 메모리를 6배 줄이고 최대 8배의 속도 향상을 제공합니다.
메타의 FAIR 연구팀과 코넬 대학교, 카네기 멜론 대학교의 연구자들이 극소수의 파라미터로도 대형 언어 모델이 추론을 학습할 수 있음을 입증했습니다. 이들은 TinyLoRA라는 새로운 방법을 소개했습니다.
AI 에이전트 개발의 현재 상태는 여러 경쟁 생태계 간의 단편화로 특징지어집니다. GitAgent는 이러한 문제를 해결하기 위한 새로운 솔루션으로 주목받고 있습니다.

NVIDIA가 Nemotron-Cascade 2를 출시했습니다. 이 모델은 30B Mixture-of-Experts(MoE) 구조로, 3B의 활성화된 매개변수를 통해 뛰어난 추론 능력을 제공합니다.

구글이 AI 에이전트가 Google Colab 환경과 직접 상호작용할 수 있는 오픈소스 MCP 서버를 출시했습니다. 이로 인해 에이전트는 클라우드 기반 Jupyter 노트북에서 Python 코드를 생성하고 수정하며 실행할 수 있는 프로그램적 접근이 가능해졌습니다.

칭화대학교와 앤트 그룹의 연구진이 자율 LLM 에이전트인 OpenClaw의 취약점을 완화하기 위한 5단계 생애주기 기반 보안 프레임워크를 공개했습니다. 이 프레임워크는 OpenClaw의 ‘커널-플러그인’ 구조의 취약점을 분석한 결과에서 출발했습니다.

바이두 치안판 팀이 40억 개 매개변수를 가진 ‘치안판-OCR’을 출시했습니다. 이 모델은 문서 파싱, 레이아웃 분석, 문서 이해를 통합하여 이미지에서 직접 Markdown으로 변환할 수 있습니다.
ORCA 컴퓨팅이 NVIDIA cuTensorNet 라이브러리와 cuQuantum SDK를 통합하여 광자 양자 시뮬레이션을 가속화하고 확장 가능한 하이브리드 워크플로를 지원합니다.

Mistral AI가 Mistral Small 4를 출시했습니다. 이 모델은 다양한 기능을 통합하여 단일 배포 대상으로 설계되었습니다. Mistral Small 4는 지시 수행, 추론, 다중 모드 이해를 결합한 첫 번째 모델입니다.
OpenViking은 AI 에이전트를 위한 오픈소스 컨텍스트 데이터베이스로, 파일 시스템 기반의 메모리와 검색 기능을 제공합니다. 이 프로젝트는 에이전트 시스템이 컨텍스트를 단순한 텍스트 덩어리로 취급하지 않도록 설계되었습니다.

구글 딥마인드가 수학 경시대회 수준을 넘어 전문 연구를 수행할 수 있는 AI 에이전트 ‘알레시아’를 선보였다. 이 AI는 자연어로 해법을 생성, 검증, 수정하며 복잡한 연구 문제를 해결한다.

스탠퍼드 대학 연구진이 기기 내에서 완전히 작동하는 개인 AI 에이전트를 개발할 수 있는 오픈소스 프레임워크 ‘OpenJarvis’를 발표했다. 이 플랫폼은 로컬 우선 AI 시스템 구축을 위한 연구 및 배포용 인프라를 제공한다.

구글이 Gemini Embedding 2를 발표했다. 이 모델은 텍스트 뿐만 아니라 이미지, 비디오, 오디오, 문서 등을 임베딩 공간으로 가져와 AI 개발자가 고차원 저장 및 교차 모달 검색 도전에 대처할 수 있도록 설계되었다.
FireRedTeam은 FireRed-OCR-2B를 발표했는데, 이 모델은 문서 구문 분석을 처리하기 위해 설계되었고, LVLM에서 발생하는 ‘구조적 환각’을 해결하는 데 사용된다.
MLflow를 사용하여 생산용 ML 실험 및 배포 워크플로우를 구축하는 튜토리얼. MLflow 추적 서버를 시작하고 구조화된 백엔드 및 아티팩트 저장소를 사용하여 실험을 추적하고, 중첩된 하이퍼파라미터 스윕을 통해 여러 머신러닝 모델을 훈련하고 자동화된 모델 평가 및 배포까지 진행.

일본의 Sakana AI가 비용 분할을 통해 제한을 우회하는 새로운 접근 방식을 제안했습니다. 최근 두 논문에서 Text-to-LoRA (T2L)과 같은 하이퍼네트워크를 소개하며, 대규모 언어 모델(LLM)의 사용을 개인화하는 과정에서 발생하는 공학적 트레이드오프를 극복했습니다.
구글이 Nano-Banana 2를 공개했다. 이 모델은 고급 주제 일관성과 초당 하위 4K 이미지 합성 성능을 특징으로 한다. 기술적으로는 Gemini 3.1 Flash Image로 지칭되며, 장치 내에서 완전히 유지되는 고품질 하위 초 이미지 합성을 지향한다.
이 튜토리얼에서는 현대 RAG 시스템이 임베딩을 분산 스토리지 노드에 샤딩하는 방식을 반영하는 탄성 벡터 데이터베이스 시뮬레이터를 구축한다. 시스템이 확장될수록 균형 잡힌 배치와 최소한의 재배치를 보장하기 위해 가상 노드로 일관된 해싱을 구현한다. 해싱 링을 실시간으로 시각화하고 노드를 대화식으로 추가하거나 제거한다.

Meta AI 연구팀이 GCM을 오픈 소스로 공개하여, 고성능 AI 훈련 및 하드웨어 신뢰성을 보장하기 위해 GPU 클러스터 모니터링을 개선하고 있다. AI 모델이 조파라미터로 확장됨에 따라, 이를 훈련하는 데 필요한 클러스터는 행성상에서 가장 복잡하고 취약한 기계 중 하나로 변화하고 있다.
최신 LangChain 에이전트 API를 사용하여 물류 디스패치 센터를 위한 생산 스타일의 경로 최적화 에이전트를 구축하는 튜토리얼. 에이전트가 추측하는 대신 거리, 도착 예정 시간 및 최적 경로를 신뢰성 있게 계산하고 결과를 구조화하여 하류 시스템에서 직접 사용할 수 있게 함.
이 튜토리얼에서는 모든 결정을 추적 가능하고 감사 가능하며 인간 승인에 의해 명시적으로 통제되는 유리 상자 형태의 에이전트 워크플로우를 구축합니다. LangGraph의 인터럽트 주도형 인간-루프 제어와 해시 체인 데이터베이스를 결합하여 고위험 작업에 대한 동적 권한 부여를 강제로 시행합니다.

구글은 Gemini 3.1 Pro를 공식 출시했는데, 이는 ‘에이전틱’ AI 시장을 겨냥한 것으로, 추론 안정성, 소프트웨어 엔지니어링, 도구 신뢰성에 초점을 맞춰 개발자들을 위한 업데이트다.

Anthropic사는 Claude 4.6 Sonnet을 발표하여 개발자와 데이터 과학자가 복잡한 논리를 다루는 방식을 변화시키고, 내부 코드 실행을 통해 실시간으로 사실을 확인하는 기능을 갖춘 Improved Web Search를 함께 선보였다.
Agoda가 APIAgent를 공개했다. 이 도구는 어떤 REST 또는 GraphQL API든 Model Context Protocol (MCP)로 변환할 수 있도록 설계되었다. AI 에이전트를 구축하는 것은 중요한 과제이지만, 데이터와의 효율적인 소통이 큰 병목 현상이다.

Exa AI가 Exa Instant를 소개했습니다. 이는 실시간 에이전틱 워크플로우에서 발생하는 병목 현상을 제거하기 위해 설계된 서브-200ms 신경 검색 엔진입니다. 대형 언어 모델(Large Language Models, LLMs) 분야에서 속도는 정확성이 해결된 후 유일하게 중요한 기능입니다.
구글 딥마인드팀이 알레테이아를 소개했다. 알레테이아는 대회 수준의 수학과 전문 연구 사이의 간극을 메우는 특수 AI 에이전트로, 2025년 국제 수학 올림피아드(IMO)에서 금메달 수준의 성과를 거두었으며, 자연 언어로 솔루션을 반복적으로 생성, 검증 및 수정하여 연구문학을 탐색하고 장기적인 증명을 구성한다.
이 튜토리얼에서는 보상 모델을 사용하지 않고 대규모 언어 모델을 인간 선호도에 맞게 조정하는 최종 Direct Preference Optimization 워크플로우를 구현한다. TRL의 DPOTrainer를 QLoRA와 PEFT와 결합하여 단일 Colab GPU에서 선호도 기반 조정을 가능하게 한다. UltraFeedback 이진화된 데이터셋에서 직접 학습을 실시한다.

OpenAI가 GPT-5.3 Codex-Spark라는 새로운 연구 미리보기를 출시했다. 이 모델은 극한 속도에 중점을 둔 것으로, 기존 GPT-5.3 Codex가 심층 추론에 초점을 맞춘 반면, Spark는 거의 즉각적인 응답 시간을 위해 설계되었다. OpenAI와 Cerebras 간의 깊은 하드웨어-소프트웨어 통합의 결과로, Spark는 게임 체인저적인 성과를 보여주고 있다.

구글이 제미니 3 딥띵크의 주요 업데이트를 발표했다. 이 업데이트는 현대 과학, 연구 및 공학을 가속화하기 위해 특별히 설계되었다. 이번 업데이트는 인류의 전문가 개입이 필요했던 문제를 내부 확인을 사용해 해결하는 ‘추론 모드’로의 전환을 대표한다.

마이크로소프트 연구자들이 ‘OrbitalBrain’ 프레임워크를 소개하여 지구 관측 인공위성이 매일 대량의 고해상도 이미지를 촬영하지만 대부분의 데이터가 지상으로 제때 전달되지 않는 문제를 해결하기 위해 우주 분산 기계 학습을 가능케 하는 방안을 제안했습니다.

바이트댄스가 Protenix-v1을 출시했다. 이 모델은 AF3 수준의 성능을 생체 분자 구조 예측에서 달성하며 코드와 모델 매개변수를 Apache 2.0 하에 공개했다.

구글과 북경대학이 공동으로 연구한 팀이 ‘PaperBanana’라는 새로운 프레임워크를 소개했다. 이 프레임워크는 멀티 에이전트 시스템을 활용하여 고품질의 학술 다이어그램을 자동화함으로써 연구자들이 복잡한 발견을 시각적으로 전달하는 과정을 개선했다.

오픈에이아이가 GPT-5.3-Codex를 소개했다. 이 모델은 코딩 및 컴퓨터 작업을 다루는 새로운 코딩 모델로, GPT-5.2-Codex의 코딩 성능과 GPT-5.2의 추론 및 전문 지식 능력을 결합하여 단일 시스템으로 운영되며 25% 빠르다.

Zero padding은 CNNs에서 사용되는 기법으로, 이미지의 가장자리 주변에 0 값을 가진 추가적인 픽셀을 추가하는 것이다. 이는 합성곱 커널이 가장자리 픽셀 위를 이동할 수 있게 하고, 합성곱 후 특징 맵의 공간적 차원이 얼마나 축소되는지를 제어하는 데 도움을 준다.

대부분의 AI 응용 프로그램은 여전히 모델을 챗박스로 보여줍니다. 그 인터페이스는 단순하지만, 에이전트가 실제로 하는 작업을 숨깁니다. 생성 UI는 채팅 상자뿐만 아니라 테이블, 차트, 양식 및 진행 표시기와 같은 실제 인터페이스 요소를 에이전트가 제어하도록 하는 것입니다.

Moonshot AI가 Kimi K2.5를 공개했다. 이 모델은 큰 Mixture of Experts 언어 기반, 네이티브 비전 인코더, 그리고 에이전트 스왐이라는 병렬 멀티 에이전트 시스템을 결합하였다. 이 모델은 코딩, 멀티모달 추론, 그리고 깊은 웹 연구에 초점을 맞추고 있으며 에이전트, 비전, 코딩 분야에서 강력한 성능을 보여준다.

Google AI가 Gemma 3 기반의 55개 언어를 지원하는 오픈 기계 번역 모델인 TranslateGemma를 출시했다. 4B, 12B, 27B 파라미터 크기로 출시되었으며, 모바일부터 노트북, 단일 H100 GPU나 TPU 인스턴스까지 다양한 디바이스에서 동작 가능하다.

이 연구는 LLM 에이전트를 위해 장기 기억에 저장할 내용, 단기 기억에 유지할 내용, 버릴 내용을 스스로 결정하는 방법을 설계하는 방법에 대해 다루고 있습니다. 이 연구에서는 텍스트 생성과 동일한 액션 공간을 통해 두 유형의 기억을 관리하는 단일 정책을 학습할 수 있는지에 대해 탐구하고 있습니다.

메타와 하버드 연구자들이 공개한 ‘컨퓨시우스 코드 에이전트’는 산업 규모 소프트웨어 저장소와 긴 코드베이스용으로 설계된 오픈 소스 AI 소프트웨어 엔지니어로, 중간 규모 언어 모델이 에이전트 구조와 도구 스택으로 이동함에 따라 혁신이 얼마나 발전할 수 있는지 보여줍니다.
이 튜토리얼에서는 Ibis를 사용하여 Pandas와 유사하지만 데이터베이스 내에서 완전히 실행되는 이식 가능한 인-데이터베이스 피처 엔지니어링 파이프라인을 구축하는 방법을 보여줍니다. DuckDB에 연결하고 데이터를 안전하게 백엔드에 등록하고 창 함수와 집계를 사용하여 복잡한 변환을 정의하는 방법을 소개합니다.

텐센트 훈유안 연구원은 HY-MT1.5를 발표했는데, 모바일 기기와 클라우드 시스템을 대상으로 하는 다국어 기계 번역 모델로, 33개 언어 간 상호 번역을 지원하며 GitHub와 Hugging Face에서 이용 가능하다.

DeepSeek 연구자들은 대형 언어 모델 교육에서 발생하는 문제를 해결하려고 노력 중이다. 새로운 방법인 mHC(Manifold Constrained Hyper Connections)은 하이퍼 연결의 풍부한 토폴로지를 유지하면서 섞임 행동을 제한함으로써 안정성을 개선한다.
Cloudflare가 tokio-quiche를 오픈소스로 공개했다. 이는 Tokio 런타임과 결합된 비동기 QUIC 및 HTTP/3 Rust 라이브러리로, Apple iCloud Private Relay, Oxy 기반 프록시, WARP의 MASQUE 클라이언트 등에서 백만 개 이상의 HTTP/3 요청을 처리하는 데 사용되었다.

텐센트의 3D 디지털 휴먼 팀이 HY-Motion 1.0을 공개했다. 이 모델은 자연어 명령과 예상 기간을 3D 인간 동작 클립으로 변환하며, 10억 개의 파라미터를 활용하여 작동한다.
이 튜토리얼에서는 무거운 프레임워크나 복잡한 인프라에 의존하지 않고 연합 학습을 사용하여 프라이버시 보호 사기 탐지 시스템을 시뮬레이션하는 방법을 보여줍니다. 10개의 독립 은행을 모방하며, 각각이 고도로 불균형한 거래 데이터에서 로컬 사기 탐지 모델을 학습합니다. 이러한 로컬 업데이트를 조율합니다.

MiniMax가 M2 모델의 향상된 버전인 MiniMax M2.1을 출시했다. 이 모델은 다중 코딩 언어 지원, API 통합, 구조화된 코딩을 위한 개선된 도구 등의 기능을 제공하며 낮은 비용으로 빠른 실행 속도를 자랑한다.

스탠포드, 하버드, UC의 최신 연구 논문인 ‘의지 있는 AI의 적응’에서는 대부분의 ‘의지 있는 AI’ 시스템이 신뢰할 수 없는 도구 사용, 약한 장기 계획, 부족한 일반화 등에 여전히 어려움을 겪고 있다고 설명하고 있다.

Anthropic이 새로운 오픈 소스 에이전틱 프레임워크 ‘Bloom’을 출시했다. 이 프레임워크는 전방위 인공지능 모델의 자동 행동 평가를 위한 것으로, 연구자가 지정한 행동을 측정하여 현실적인 시나리오에서 얼마나 자주 강도 있게 나타나는지 측정한다. ‘Bloom’의 등장은 안전 및 정렬을 위한 행동 평가가 설계 및 유지에 비용이 많이 드는 문제를 해결한다.

Mistral AI가 최신 OCR 서비스인 Mistral OCR 3를 출시했다. 이 모델은 PDF 및 기타 문서에서 교차된 텍스트와 이미지를 추출하고 구조를 보존하는 데 사용되며, 1,000 페이지 당 $2의 저렴한 가격에 이를 수행한다.

Meta사가 SAM Audio를 발표했는데, 이는 진행이 어려운 오디오 분리 문제를 해결하기 위한 모델로, 사용자 친화적이고 멀티모달 프롬프트를 활용한다. 세 가지 사이즈로 제공되며, 다운로드 및 사용이 가능하다.

OpenAI팀이 Hugging Face에서 openai/circuit-sparsity 모델과 GitHub에서 openai/circuit_sparsity 툴킷을 공개했다. ‘Weight-sparse transformers have interpretable circuits’ 논문의 모델과 회로를 패키징했는데, 이는 Python 코드로 훈련된 GPT-2 스타일 디코더 전용 트랜스포머다. 희소성은 훈련 후에 추가되지 않았다.

Boss Zhipin의 Nanbeige LLM Lab이 발표한 Nanbeige4-3B는 데이터 품질, 커리큘럼 스케줄링, 디스틸레이션, 강화 학습에 중점을 둔 3B 파라미터 작은 언어 모델 패밀리로, 30B 클래스 추론을 제공하는 훈련 레시피를 수정함으로써 가능한가에 대한 연구 결과를 소개한다.
구글과 MediaTek의 새 LiteRT NeuroPilot 가속기는 실제 생성 모델을 폰, 랩탑 및 IoT 하드웨어에서 데이터 센터로 요청을 보내지 않고 실행할 수 있는 구체적인 단계입니다. 기존의 LiteRT 런타임을 채택하여 MediaTek의 NeuroPilot NPU 스택에 직접 연결하여 개발자가 LLMs와 임베딩 모델을 배포할 수 있습니다.
구글이 캐글과 코랩 사이의 간극을 메우기 위해 새로운 기능인 코랩 데이터 익스플로러를 출시했다. 이를 통해 노트북 내에서 캐글 데이터셋, 모델, 대회를 검색하고 편집기를 벗어나지 않고 캐글허브를 통해 가져올 수 있다.
Panel을 활용해 고급 다중 페이지 인터랙티브 대시 보드를 만드는 튜토리얼. 각 구성 요소를 통해 합성 데이터 생성, 풍부한 필터 적용, 동적 시계열 트렌드 시각화, 세그먼트 및 지역 비교, 그리고 실시간 KPI 업데이트 시뮬레이션 방법을 탐구한다.

메타 AI 연구원들이 소개한 매트릭스는 현대 AI 모델을 위해 합성 데이터를 신선하고 다양하게 유지하는 방법을 제시하는데, 단일 조율 파이프라인을 병목 현상으로 만들지 않고, 분산된 대기열을 통해 메시지로 직렬화된 제어와 데이터 흐름을 구현한 분산 프레임워크이다.

NVIDIA 연구진이 ToolOrchestra를 발표했습니다. 이는 각 작업 단계마다 올바른 모델 또는 도구를 선택하는 AI 시스템을 어떻게 학습시킬 수 있는지에 대한 혁신적인 방법입니다.
Tinygrad를 사용하여 텐서, 오토그래드, 어텐션 메커니즘 및 트랜스포머 구조를 완전히 손으로 만들어보는 튜토리얼. 기본 텐서 작업부터 멀티헤드 어텐션, 트랜스포머 블록, 미니-GPT 모델까지 순차적으로 구축하면서 Tinygrad의 간결함을 관찰한다.

마이크로소프트 연구팀이 7조 개의 파라미터를 가진 Fara-7B를 발표했다. 이 모델은 컴퓨터 사용을 위해 특별히 설계된 작은 언어 모델로, 클라우드로 데이터를 보내지 않고도 AI 에이전트가 웹 작업을 처리할 수 있게 해준다.