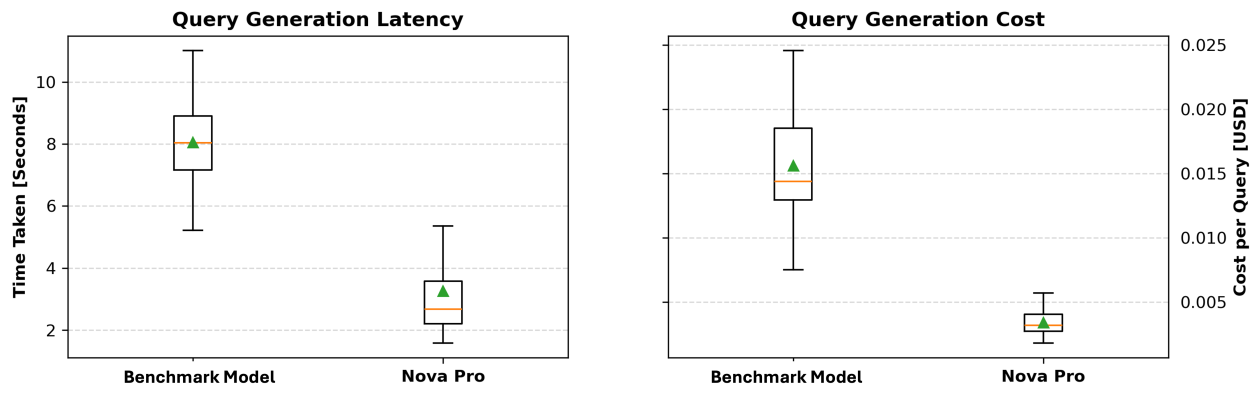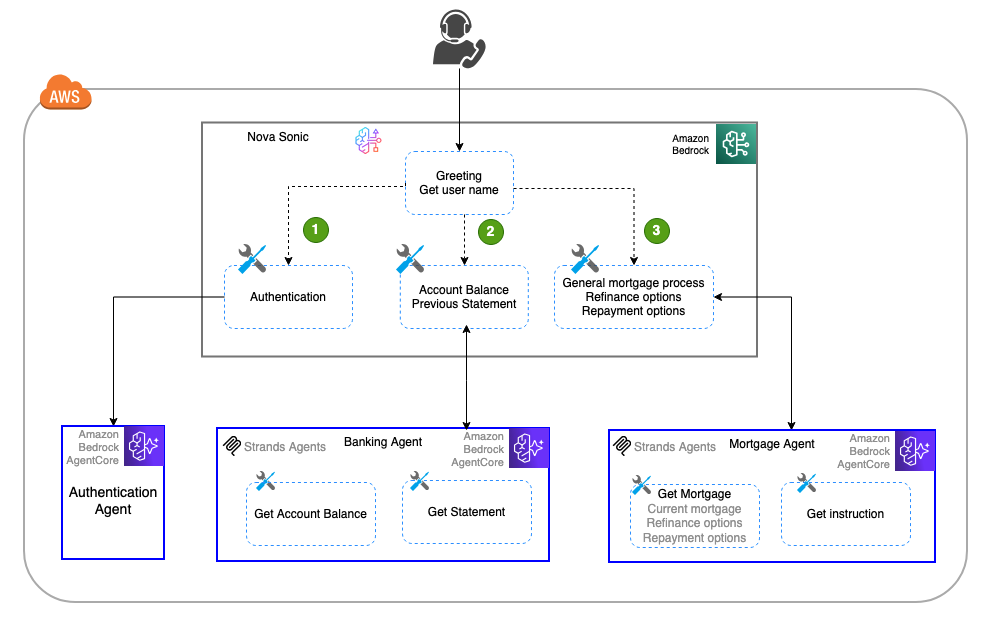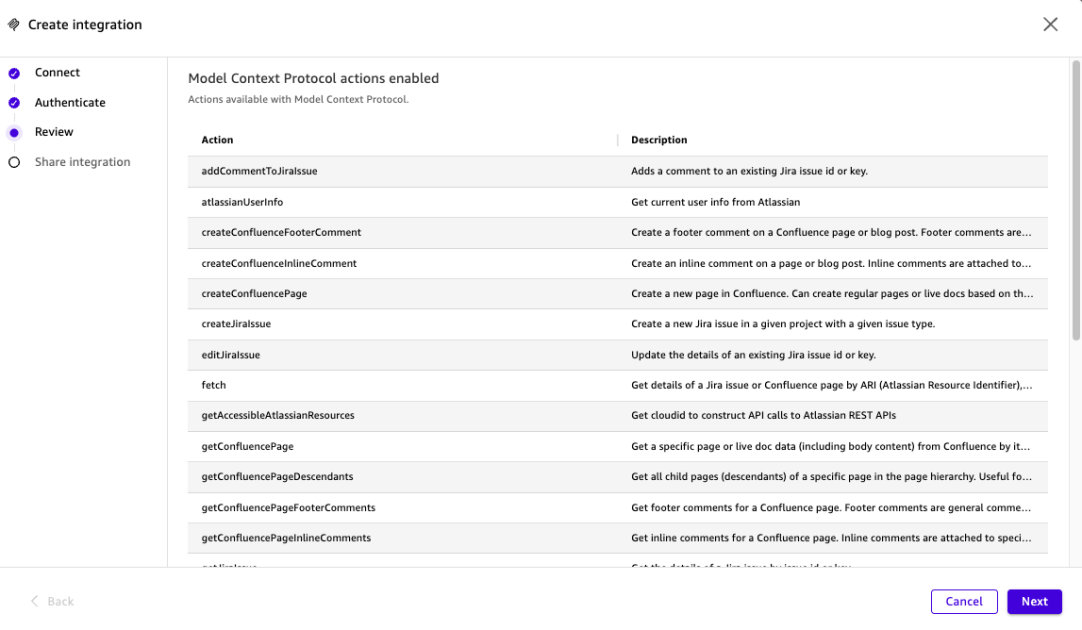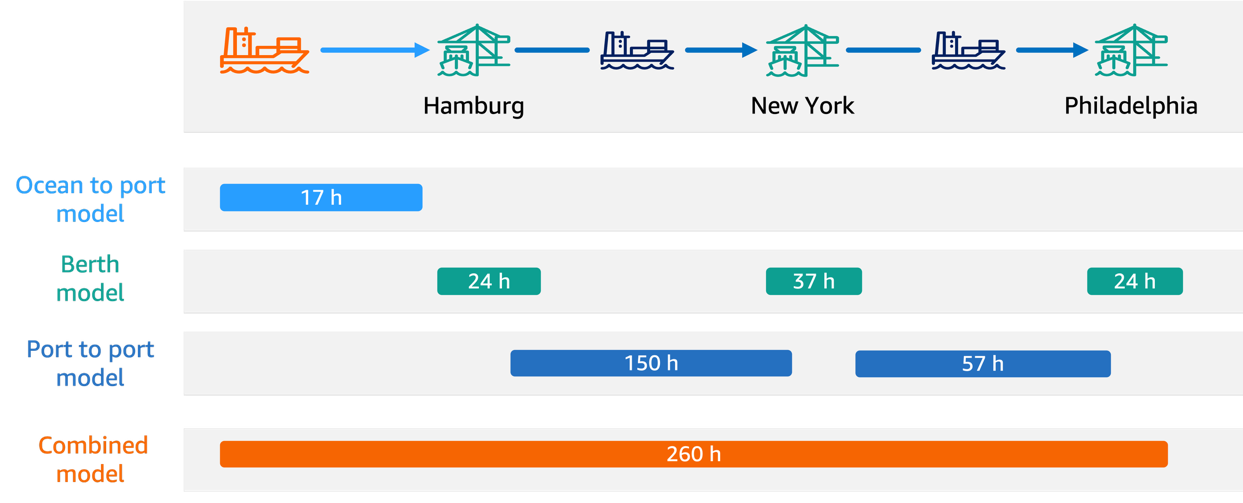







구글 AI가 FLAME 접근 방식을 소개: 가장 정보가 풍부한 샘플을 선택하여 모델 전문화를 빠르게 만듬
구글 연구팀이 FLAME을 제안했는데, 이는 강력한 오픈 어휘 탐지기를 기반으로 한 단일 단계의 액티브 러닝 전략으로, 훈련할 수 있는 작은 정교화기를 추가하여 가장 정보가 풍부한 샘플을 선택하고 모델 전문화를 빠르게 만드는 방법이다.
2025년 10월 23일 오후 6시 44분