






바이트댄스 연구원들, 프로토리즈닝 소개: 논리 기반 프로토타입을 통한 LLM 일반화 향상
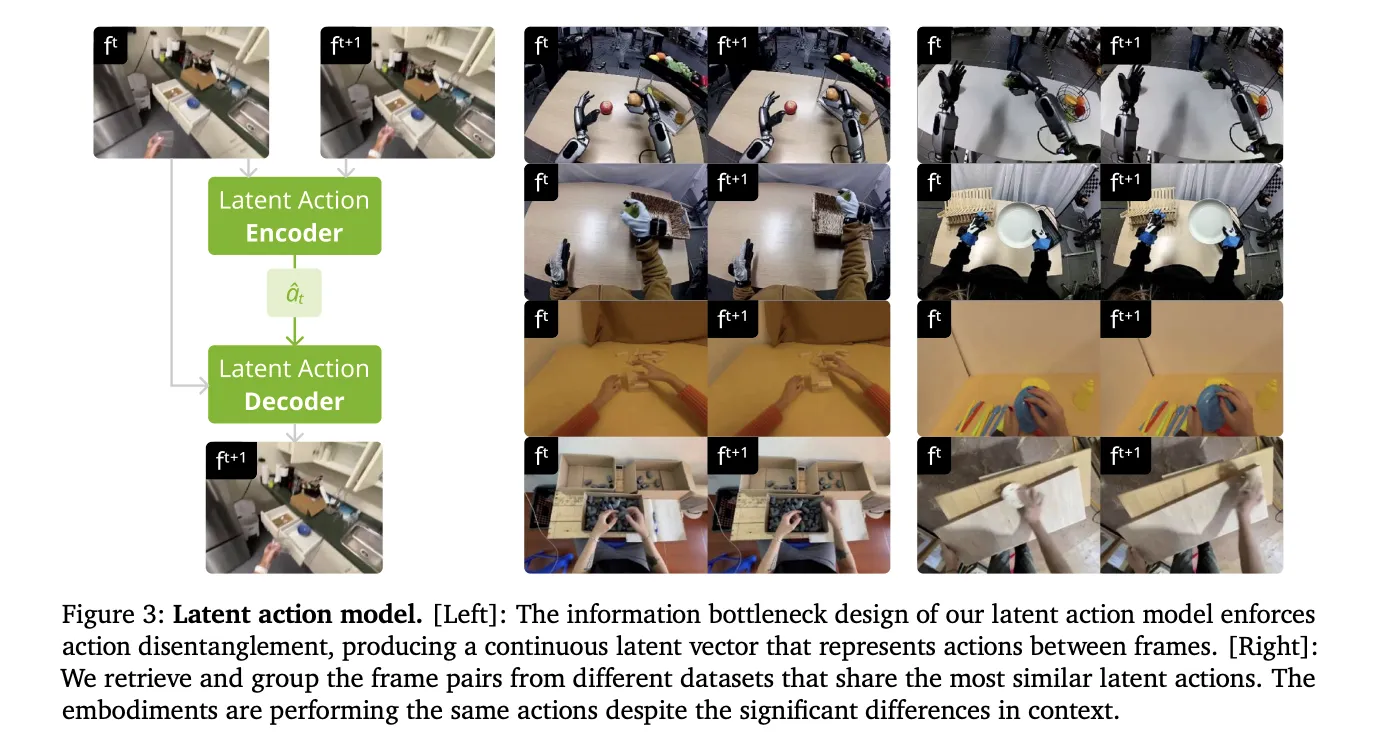
바이트댄스 연구자들이 프로토리즈닝을 소개했는데, 이는 LLM(대규모 언어 모델)의 일반화를 논리 기반 프로토타입을 통해 향상시키는 것이다. 최근 LRM의 교차 도메인 추론이 중요한데, 특히 Long CoT 기술을 사용해 훈련된 모델들은 다양한 도메인에서 인상적인 일반화를 보여준다.
2025년 6월 24일 오후 5시 37분






















































































