‘kvcached’ 만나보기: 공유 GPU에서 LLM 서빙을 위한 가상화된 탄력있는 KV 캐시를 가능하게 하는 머신러닝 라이브러리
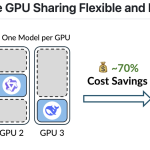
최근 대형 언어 모델(Large Language Model, LLM) 서빙은 GPU 메모리를 낭비하는 문제가 있었습니다. 각 모델은 요청이 폭주적이거나 유휴 상태일 때에도 큰 정적 KV 캐시 영역을 미리 예약하게 되어 있었기 때문입니다. 하지만 버클리 스카이 컴퓨팅 연구소(University of Berkeley’s Sky Computing Lab)에서 개발한 ‘kvcached’는 공유 GPU에서 LLM 서빙을 위해 가상화된 탄력있는 KV 캐시를 가능하게 하는 머신러닝 라이브러리입니다. 이를 통해 GPU 메모리를 효율적으로 활용할 수 있게 되었습니다.
#AIInfrastructure #AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #DeepLearning #EditorsPick #LanguageModel #Machinelearning #NewReleases #OpenSource #Python #TechNews #Technology
출처: Mark Tech Post
요약번역: 미주투데이 김지호 기자