




알리바바, 자율 AI 에이전트 실행을 위한 통합, 안전하고 확장 가능한 API 제공하는 OpenSandbox 출시
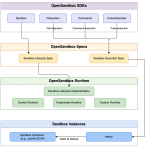
알리바바가 오픈소스 도구인 OpenSandbox를 출시했습니다. 이 도구는 AI 에이전트에 안전하고 격리된 환경을 제공하여 코드 실행, 웹 브라우징, 모델 훈련을 가능하게 합니다. Apache 2.0 라이선스 하에 공개된 OpenSandbox는 AI 에이전트 스택의 ‘실행 레이어’를 표준화하고 여러 프로그래밍 언어에서 작동하는 통일된 API를 제공합니다.
2026년 3월 3일 오전 3시 32분








