
Miso Labs, 오픈 웨이트 기반의 8B 감정 텍스트 음성 변환 모델 MisoTTS 출시
Miso Labs가 오픈 웨이트를 기반으로 한 8B 텍스트 음성 변환 모델 MisoTTS를 출시했습니다. 이 모델은 텍스트와 오디오 맥락을 기반으로 화자의 톤에 맞춰 반응합니다.
2026년 6월 4일 오후 5시 11분

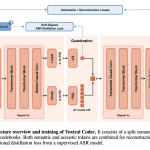





Miso Labs가 오픈 웨이트를 기반으로 한 8B 텍스트 음성 변환 모델 MisoTTS를 출시했습니다. 이 모델은 텍스트와 오디오 맥락을 기반으로 화자의 톤에 맞춰 반응합니다.
2026년 텍스트 음성 변환(TTS) 기술이 빠르게 발전했습니다. 이 가이드는 상업용 및 오픈 소스 TTS 모델을 품질, 지연 시간, 비용, 언어 지원 및 라이센스 기준으로 비교하여 엔지니어들이 적합한 모델을 선택할 수 있도록 돕습니다.

서울에 본사를 둔 음성 AI 기업 수퍼톤이 새로운 TTS 엔진 Supertonic v3를 출시했습니다. 이번 모델은 표현 태그와 향상된 읽기 안정성을 제공하며, 언어 지원 범위가 6배 확대되었습니다.
OpenAI가 실시간 API에서 GPT-Realtime-2, GPT-Realtime-Translate, GPT-Realtime-Whisper 등 세 가지 오디오 모델을 출시했습니다. 이 모델들은 실시간 음성을 활용한 다양한 기능을 제공합니다.
인월드 AI가 새로운 음성 모델인 실시간 TTS-2를 출시했습니다. 이 모델은 단순한 전사본이 아닌 전체 오디오 맥락을 기반으로 작동하여 음성 기반 AI 에이전트의 구조적 변화를 가져옵니다.
Mistral의 Voxtral TTS는 기존 음성 합성 시스템의 한계를 극복하고 감정과 리듬을 살린 자연스러운 음성을 제공하는 혁신적인 기술입니다.
xAI의 새로운 음성 모델 grok-voice-think-fast-1.0이 소매, 항공사, 통신 분야에서 Gemini와 GPT Realtime을 초과 성능을 보였습니다.
이 튜토리얼에서는 Deepgram Python SDK를 사용하여 전사, 음성 합성, 비동기 오디오 처리 및 텍스트 인텔리전스의 고급 워크플로우를 구축하는 방법을 설명합니다.

일론 머스크의 AI 회사 xAI가 독립형 음성 인식(STT) 및 음성 합성(TTS) API를 출시했습니다. 이 API는 Grok Voice의 인프라를 기반으로 하며, 기업 음성 개발자를 겨냥하고 있습니다.
구글이 Gemini 3.1 Flash TTS를 출시하며 음성 품질과 표현력, 다국어 생성 능력을 개선한 텍스트-음성 변환 모델을 선보였습니다. 이 모델은 70개 이상의 언어를 지원하며, 자연어 오디오 태그와 다중 화자 대화 기능을 갖추고 있습니다.
이 튜토리얼에서는 Microsoft VibeVoice를 사용하여 음성 인식과 실시간 음성 합성을 위한 워크플로우를 구축하는 방법을 소개합니다. 환경 설정부터 최신 모델 지원 확인까지 단계별로 안내합니다.
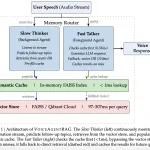
세일즈포스 AI 연구팀이 음성 AI의 반응 속도를 획기적으로 개선하는 VoiceAgentRAG를 발표했다. 이 기술은 음성 기반 RAG 시스템의 지연 시간을 크게 줄여 자연스러운 대화 흐름을 유지할 수 있도록 돕는다.

구글이 개발자들을 위해 ‘제미니 3.1 플래시 라이브’를 공개했습니다. 이 모델은 저지연의 자연스러운 음성 상호작용을 목표로 하며, 멀티모달 스트림을 처리할 수 있는 기술적 기반을 제공합니다.

텐센트 AI 연구소가 7B 매개변수를 가진 Covo-Audio라는 음성 언어 모델을 공개했습니다. 이 모델은 연속 오디오 입력을 처리하고 오디오 출력을 생성하는 통합 아키텍처를 제공합니다.
구글과 연구팀이 아프리카 언어를 위한 다국어 음성 데이터셋 WAXAL을 발표했다. 이 데이터셋은 24개 언어를 포함하며, 자동 음성 인식 및 텍스트 음성 변환 모델 훈련에 활용될 예정이다.
IBM이 다국어 자동 음성 인식 및 번역을 위한 컴팩트한 음성 모델 Granite 4.0 1B Speech를 출시했습니다. 이 모델은 메모리 사용량과 지연 시간, 계산 효율성을 중시하는 기업 및 엣지 스타일의 음성 배포를 목표로 하고 있습니다.
텐센트 훈유안 연구원은 HY-MT1.5를 발표했는데, 모바일 기기와 클라우드 시스템을 대상으로 하는 다국어 기계 번역 모델로, 33개 언어 간 상호 번역을 지원하며 GitHub와 Hugging Face에서 이용 가능하다.
이 튜토리얼에서는 실시간으로 자연어를 통해 이해, 추론 및 응답이 가능한 의지를 갖춘 음성 AI 어시스턴트를 구축하는 방법을 탐구합니다. 음성 인식, 의도 감지, 다단계 추론 및 텍스트 음성 합성을 통합하는 자체 음성 인텔리전스 파이프라인을 설정하는 것부터 시작하여, 우리는 듣고 반응하며 디자인합니다.
Neuphonic이 NeuTTS Air를 공개했는데, 이는 748M 파라미터(큐윈2 아키텍처)를 갖춘 오픈소스 텍스트 음성 변환 모델로, 클라우드 의존성 없이 CPU에서 실시간으로 실행될 수 있다. Apache-2.0 라이선스 하에 제공되며, 러너블 데모와 함께 제공된다.
WhisperX를 활용한 음성 AI 파이프라인의 고급 구현 방법을 안내하는 튜토리얼. 전사, 정렬, 단어별 타임스탬프에 대해 자세히 살펴보며 환경 설정, 오디오 로드 및 전처리, 전사에서 정렬 및 분석까지의 전체 파이프라인 실행과 메모리 효율성 및 배치 처리 지원에 대해 다룸.
음성 AI는 멀티모달 AI에서 중요한 분야 중 하나로 부상하고 있으며, 기계가 인간과 상호작용하는 방식을 재구성하고 있다. 그러나 모델은 빠르게 발전했지만 그 평가 도구는 발전하지 못했다. UT Austin과 ServiceNow 연구팀은 AU-Harness를 발표함.
캘리포니아 소재 음성 AI 스타트업 TwinMind은 Ear-3 음성 인식 모델을 공개하며 탁월한 성능과 다국어 지원을 주장하고 있다. Ear-3은 Deepgram, AssemblyAI, Eleven Labs, Otter, Speechmatics, OpenAI와 같은 기존 ASR 솔루션에 대항하는 경쟁력 있는 제품으로 소개되었다.
2025년 음성 AI 기술은 실시간 대화형 AI, 감정 지능, 음성 합성 등에서 혁명적인 발전을 이루었습니다. 기업들이 음성 에이전트를 점점 채택하고 소비자들이 차세대 AI 어시스턴트를 수용함에 따라 각 산업 전문가들에게 최신 소식에 대한 정보 파악이 중요해졌습니다. 글로벌 음성 AI 시장은 54억 달러에 이르렀습니다.
Microsoft AI 연구소가 MAI-Voice-1과 MAI-1-Preview를 공식 발표하며 인공지능 연구 및 개발 노력의 새로운 단계를 마련했다. MAI-Voice-1과 MAI-1-Preview 모델은 음성 합성과 일반적인 언어 이해에 각각 고유한 역할을 지원한다.
2025년은 음성 AI 에이전트에 대한 전환점으로, 10년 전에는 상상도 못했던 자연스러움, 문맥 이해, 상용 채택 수준의 기술이 도래했다. 음성 인식, 자연어 이해, 다중 모달 통합 등의 큰 발전을 통해 음성 AI는 더 이상 명령 및 질의 시스템에 한정되지 않고 중심적 인터페이스로 신속히 발전하고 있다.