NVIDIA, 3가지 모드를 지원하는 언어 모델 ‘Nemotron-Labs-Diffusion’ 발표
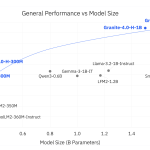
NVIDIA가 3가지 디코딩 모드를 통합한 언어 모델 ‘Nemotron-Labs-Diffusion’을 출시했습니다. 이 모델은 3B, 8B, 14B 파라미터 크기로 제공되며, 자율 회귀, 확산 기반 병렬 디코딩, 자기 추측 디코딩을 지원합니다.
2026년 5월 20일 오후 7시 41분