퍼플렉시티 AI, 개인용 컴퓨터를 위한 하이브리드 로컬-서버 추론 오케스트레이터 발표
퍼플렉시티 AI가 개인용 컴퓨터를 위한 하이브리드 로컬-서버 추론 오케스트레이터를 발표했다. 이 시스템은 AI 작업을 자동으로 온디바이스와 클라우드 모델 간에 라우팅한다.
2026년 6월 5일 오후 6시 44분










퍼플렉시티 AI가 개인용 컴퓨터를 위한 하이브리드 로컬-서버 추론 오케스트레이터를 발표했다. 이 시스템은 AI 작업을 자동으로 온디바이스와 클라우드 모델 간에 라우팅한다.
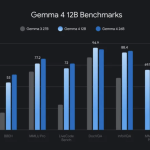
구글 딥마인드가 비전과 오디오를 직접 LLM 백본에 연결하는 인코더 없는 멀티모달 모델 ‘Gemma 4 12B’를 발표했다. 이 모델은 Apache 2.0 라이선스 하에 로컬에서 실행된다.

마이크로소프트 리서치가 클릭 추적 웹 자동화를 대체하는 터미널 기반 브라우저 에이전트 프레임워크 ‘웹라이트’를 발표했다. 이 프레임워크는 GPT-5.4를 기반으로 하여 Odysseys 벤치마크에서 60.1%의 점수를 기록했다.

알리바바의 Qwen 팀이 Qwen3.5-LiveTranslate-Flash를 출시했습니다. 이 모델은 60개 언어를 지원하며, 2.8초의 지연 시간으로 오디오와 비디오를 동시에 처리합니다.
Poetiq의 메타 시스템이 Gemini 3.1 Pro를 사용해 LiveCodeBench Pro를 위한 모델 비의존적 추론 하네스를 자동으로 구축하고 최적화했습니다. 이 하네스는 다른 모델에도 적용되어 모두 성능이 향상되었습니다.
MedAIBase가 1030억 개 매개변수를 가진 오픈소스 의료 언어 모델 AntAngelMed를 발표했다. 이 모델은 1/32 활성화 비율의 Mixture-of-Experts 아키텍처를 사용하여 효율적인 성능을 자랑한다.
OpenAI가 사이버 보안 이니셔티브 ‘데이브레이크’를 출시했습니다. 이 프로그램은 Codex Security와 AI 모델을 결합하여 소프트웨어 취약점을 조기에 발견하고 수정할 수 있도록 지원합니다.
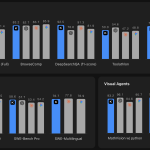
중국의 AI 연구소 문샷 AI가 Kimi K2.6을 오픈 소스 형태로 출시했습니다. 이 모델은 자율적으로 소프트웨어 공학 문제를 해결하는 데 중점을 두고 있으며, 장기 코딩 에이전트와 자연어 기반 프론트엔드 생성 기능을 제공합니다.
OpenAI가 생명과학 분야에 진출하며, 약물 발견과 유전체 연구를 가속화하기 위해 GPT-Rosalind라는 AI 모델을 출시했습니다. 이 모델은 10-15년의 약물 발견 기간을 단축할 것으로 기대됩니다.
구글이 Gemini 3.1 Flash TTS를 출시하며 음성 품질과 표현력, 다국어 생성 능력을 개선한 텍스트-음성 변환 모델을 선보였습니다. 이 모델은 70개 이상의 언어를 지원하며, 자연어 오디오 태그와 다중 화자 대화 기능을 갖추고 있습니다.
구글 AI 연구팀이 협업, 창의성, 비판적 사고를 측정하기 위한 LLM 기반의 Vantage 프로토콜을 제안했다. 기존의 표준화된 테스트로는 이러한 내구성 있는 기술을 평가하기 어렵다는 점을 강조하고 있다.
AI 연구 회사 MiniMax가 MMX-CLI를 출시했습니다. 이 커맨드라인 인터페이스는 AI 에이전트가 이미지, 비디오, 음성, 음악, 비전 및 검색 기능에 접근할 수 있도록 지원합니다.

Liquid AI가 새로운 비전-언어 모델 LFM2.5-VL-450M을 출시했다. 이 모델은 바운딩 박스 예측, 다국어 지원, 250ms 이하의 엣지 추론 기능을 갖추고 있다.
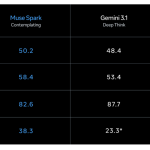
메타 슈퍼인텔리전스 연구소가 ‘뮤즈 스파크’를 발표했습니다. 이 모델은 도구 사용, 시각적 사고 과정, 다중 에이전트 조정을 지원하는 멀티모달 추론 모델입니다.
IBM이 기업급 문서 데이터 추출을 위해 설계된 비전-언어 모델인 Granite 4.0 3B 비전을 출시했습니다. 이 모델은 고충실도의 시각적 추론을 제공하는 전문 어댑터로 구성되어 있습니다.
Hugging Face가 TRL(Transformer Reinforcement Learning) v1.0을 공식 출시했습니다. 이 버전은 연구 중심의 라이브러리에서 안정적인 프로덕션 준비 프레임워크로의 전환을 의미합니다.
구글이 비디오 생성 포트폴리오의 새로운 모델인 Veo 3.1 Lite를 발표했다. 이 모델은 생산 규모 배포의 주요 장애물인 가격 문제를 해결하기 위해 설계되었다.
Liquid AI가 LFM2.5-350M 모델을 출시했습니다. 이 모델은 28T 토큰으로 훈련된 350M 파라미터의 컴팩트한 구조로, 기존의 스케일링 법칙에 도전하는 사례로 주목받고 있습니다.
알리바바 Qwen 팀이 Qwen3.5-Omni를 출시했습니다. 이 모델은 텍스트, 오디오, 비디오를 통합하여 실시간 상호작용을 지원하는 멀티모달 언어 모델로, 기존의 모델들과 차별화된 점이 있습니다.
마이크로소프트가 다양한 언어에 대한 고품질 의미 표현을 제공하는 다국어 텍스트 임베딩 모델 Harrier-OSS-v1을 발표했다. 이 모델은 270M, 0.6B, 27B의 세 가지 규모로 제공된다.

에이전트 인프라가 AI 에이전트를 위한 올인원 런타임인 AIO 샌드박스를 공개했습니다. 이 오픈소스 프로젝트는 코드 실행을 위한 기능적이고 격리된 환경을 제공합니다.

아마존 연구팀이 자율 AI 에이전트 개발을 자동화하는 A-Evolve라는 인프라를 발표했습니다. 이 프레임워크는 수동 조정 대신 자동화된 진화 과정을 통해 에이전트 개발을 혁신할 것으로 기대됩니다.

Mistral AI가 오픈 웨이트 텍스트-투-스피치 모델인 Voxtral TTS를 출시했습니다. 이는 회사의 오디오 생성 분야로의 첫 번째 주요 진출로, 개발자 생태계에서 독점 음성 API와의 경쟁을 목표로 하고 있습니다.
openJiuwen 커뮤니티가 자가 진화하는 AI 에이전트 ‘JiuwenClaw’를 출시했습니다. 이 AI는 실제 작업을 수행하는 데 중점을 두고 개발되었습니다.

코히어가 새로운 자동 음성 인식 모델 ‘코히어 트랜스크라이브’를 출시하며 기업 AI 시장에 진입했습니다. 이 모델은 비구조화된 오디오를 실용적인 텍스트로 변환하는 데 도움을 줍니다.

텐센트 AI 연구소가 7B 매개변수를 가진 Covo-Audio라는 음성 언어 모델을 공개했습니다. 이 모델은 연속 오디오 입력을 처리하고 오디오 출력을 생성하는 통합 아키텍처를 제공합니다.
구글이 대형 언어 모델의 메모리 통신 오버헤드를 줄이기 위해 TurboQuant라는 새로운 압축 알고리즘을 발표했습니다. 이 알고리즘은 LLM의 키-값 캐시 메모리를 6배 줄이고 최대 8배의 속도 향상을 제공합니다.
루마랩스가 기존의 확산 파이프라인의 ‘의도 격차’를 해결하기 위해 구조적 추론이 가능한 이미지 모델 ‘유니-1’을 출시했다. 이 모델은 이미지 생성 전에 추론 단계를 도입하여 새로운 워크플로우를 제시한다.

NVIDIA가 Nemotron-Cascade 2를 출시했습니다. 이 모델은 30B Mixture-of-Experts(MoE) 구조로, 3B의 활성화된 매개변수를 통해 뛰어난 추론 능력을 제공합니다.

바이두 치안판 팀이 40억 개 매개변수를 가진 ‘치안판-OCR’을 출시했습니다. 이 모델은 문서 파싱, 레이아웃 분석, 문서 이해를 통합하여 이미지에서 직접 Markdown으로 변환할 수 있습니다.

언슬로스 AI가 고성능 대형 언어 모델(LLM) 미세 조정을 위한 로컬 노코드 인터페이스 ‘언슬로스 스튜디오’를 출시했습니다. 이 스튜디오는 VRAM 사용량을 70% 줄여 효율성을 높입니다.

Mistral AI가 Mistral Small 4를 출시했습니다. 이 모델은 다양한 기능을 통합하여 단일 배포 대상으로 설계되었습니다. Mistral Small 4는 지시 수행, 추론, 다중 모드 이해를 결합한 첫 번째 모델입니다.

문샷 AI 연구팀이 변환기 모델의 성능 향상을 위해 깊이별 주의를 활용한 새로운 잔여 연결 방식을 발표했습니다. 이 방식은 기존의 고정 잔여 혼합 방식의 구조적 문제를 해결하는 데 중점을 두고 있습니다.

로봇들이 GPT-3 시대로 진입하고 있습니다. 연구자들은 오랫동안 로봇을 대규모 언어 모델 (LLM)을 구동하는 자기 회귀(AR) 모델을 사용하여 훈련하려고 노력해왔습니다. 모델이 문장에서 다음 단어를 예측할 수 있다면 로봇 팔의 다음 움직임도 예측할 수 있어야 합니다. 그러나 기술적 한계가 있었습니다.

오픈에이아이가 GPT-5.3-Codex를 소개했다. 이 모델은 코딩 및 컴퓨터 작업을 다루는 새로운 코딩 모델로, GPT-5.2-Codex의 코딩 성능과 GPT-5.2의 추론 및 전문 지식 능력을 결합하여 단일 시스템으로 운영되며 25% 빠르다.

알리바바의 Qwen3-Max-Thinking은 파라미터 규모를 확장하는 것뿐만 아니라, 추론 방식을 변화시키며 생각의 깊이에 대한 명시적 제어와 검색, 메모리, 코드 실행을 위한 내장 도구를 갖추고 있습니다. 이 모델은 36조 토큰에 사전 훈련된 1조 파라미터 MoE 플래그십 LLM으로, 데이터 및 배포 측면에서 Qwen3-Max-Thinking은 […]
Inworld AI가 실시간 음성 에이전트에 대한 업그레이드 된 Inworld TTS-1.5를 출시했다. TTS-1.5는 지연 시간, 품질 및 비용에 엄격한 제약 조건을 가진 음성 에이전트를 대상으로 하며, 인공 분석에서 최고 순위의 텍스트 음성 변환 시스템으로 소개되었다. 이전 세대보다 표현이 풍부하고 안정적이며, 더욱 향상된 디자인을 가지고 있다.

Meta 연구진은 PEAV(Perception Encoder Audiovisual)를 소개했는데, 이는 오디오와 비디오의 통합 이해를 위한 새로운 인코더 패밀리로, 약 100M개의 오디오 비디오 쌍과 텍스트 캡션을 대규모 대조적 학습을 통해 단일 임베딩 공간에서 정렬된 오디오, 비디오 및 텍스트 표현을 학습한다.
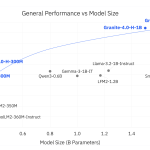
IBM AI 팀이 Granite 4.0 Nano를 출시했다. 이 모델은 로컬 및 엣지 추론을 대상으로 하는 소형 모델로, 기업 제어 및 오픈 라이선스를 갖추고 있으며, 350M과 1B 정도의 두 가지 크기의 8개 모델로 구성되어 있다.
KTH의 Speech, Music and Hearing 그룹이 공개한 VoXtream은 실시간 TTS 모델로, 사람이 음성을 듣기 전에 잠시의 침묵 없이 말을 시작한다. 이는 실시간 에이전트, 실시간 더빙, 동시 통역 등에 혁명을 일으킬 것으로 기대된다.
Xiaomi의 MiMo 팀이 100백만 시간 이상의 오디오를 기반으로 한 7조 파라미터 음성 언어 모델 ‘MiMo-Audio’를 공개했다. 새로운 점은 과업별 헤드나 손실 악센트 토큰에 의존하는 대신, RVQ 토크나이저를 사용하여 의미론적 정보 및 음성을 타깃팅한다.
AI2, 워싱턴대학 및 CMU의 연구진이 유동 벤치마킹을 소개하며, 정적 정확도를 2개 매개변수 IRT 능력 추정 및 Fisher 정보 기반 항목 선택으로 대체하는 적응형 LLM 평가 방법을 도입했다. 모델의 현재 능력에 대해 가장 정보가 풍부한 질문만 하므로 더 부드러운 훈련 곡선을 제공하고 벤치마킹을 지연시킵니다.
알리바바 클라우드의 Qwen 팀이 Qwen3-ASR Flash를 공개했다. 이는 Qwen3-Omni의 강력한 지능을 기반으로 한 올인원 자동 음성 인식(ASR) 모델로, 여러 시스템을 번갈아가며 사용하지 않고 다국어, 소음, 도메인별 전사를 간단하게 처리한다. 주요 기능은 edtech 플랫폼(강의 캡처, 다국어 지도), 미디어(자막, 성우), 고객 서비스(다국어 IVR) 등이다.
텐센트의 훈유안팀이 훈유안-MT-7B(번역 모델) 및 훈유안-MT-Chimera-7B(앙상블 모델)을 공개했다. 두 모델은 다국어 기계 번역을 위해 특별히 설계되었으며, WMT2025 General Machine Translation 대회에서 훈유안-MT-7B가 31개 언어 쌍 중 30개에서 1위를 차지했다.

FlexOlmo는 데이터를 공유하지 않고도 대규모 언어 모델을 개발할 수 있는 방법을 제시하며, 공개되지 않거나 제한이 있는 데이터셋에 대한 의존성을 줄입니다.

Mistral AI가 Voxtral을 발표했다. Voxtral은 오디오와 텍스트 입력을 처리하는 Voxtral-Small-24B 및 Voxtral-Mini-3B 모델로, 자동 음성 인식(ASR)과 자연어 이해 기능을 통합한다. Apache 2.0 라이선스로 공개된 Voxtral은 전사, 요약, 질문 응답 등에 실용적인 솔루션을 제공한다.

밀도 기능 이론(DFT)은 현대 계산 화학과 재료 과학의 기초 역할을 합니다. 그러나 높은 계산 비용으로 인해 사용이 제한됩니다. 기계 학습 상호 원자력(MLIP)은 DFT 정확도를 근접하게 흉내내며 계산 시간을 현저히 단축시키는 잠재력이 있습니다.

Kyutai가 2조 개의 파라미터로 구성된 혁신적인 스트리밍 텍스트 음성 변환 모델을 발표했습니다. 이 모델은 초저지연 시간(220밀리초)으로 고품질의 오디오 생성을 제공하며 전례없는 2.5백만 시간의 오디오로 훈련되었습니다. CC-BY-4.0에 따라 라이선스가 부여되었습니다.