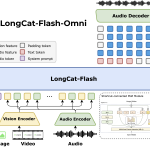
구글 딥마인드, Lyria 3 출시: 포함된 가사와 보컬이 담긴 사용자 지정 트랙으로 사진과 텍스트를 변환하는 고급 음악 생성 AI 모델
구글 딥마인드가 음악 분야에서도 창의적 AI의 한계를 넓혔다. Lyria 3은 사진과 텍스트를 이용해 사용자 맞춤 트랙을 생성하는 고급 음악 생성 모델로, 복잡한 오디오 파형과 창의적 의도를 다루는데 큰 전환점을 제공한다.
2026년 2월 18일 오후 3시 10분