



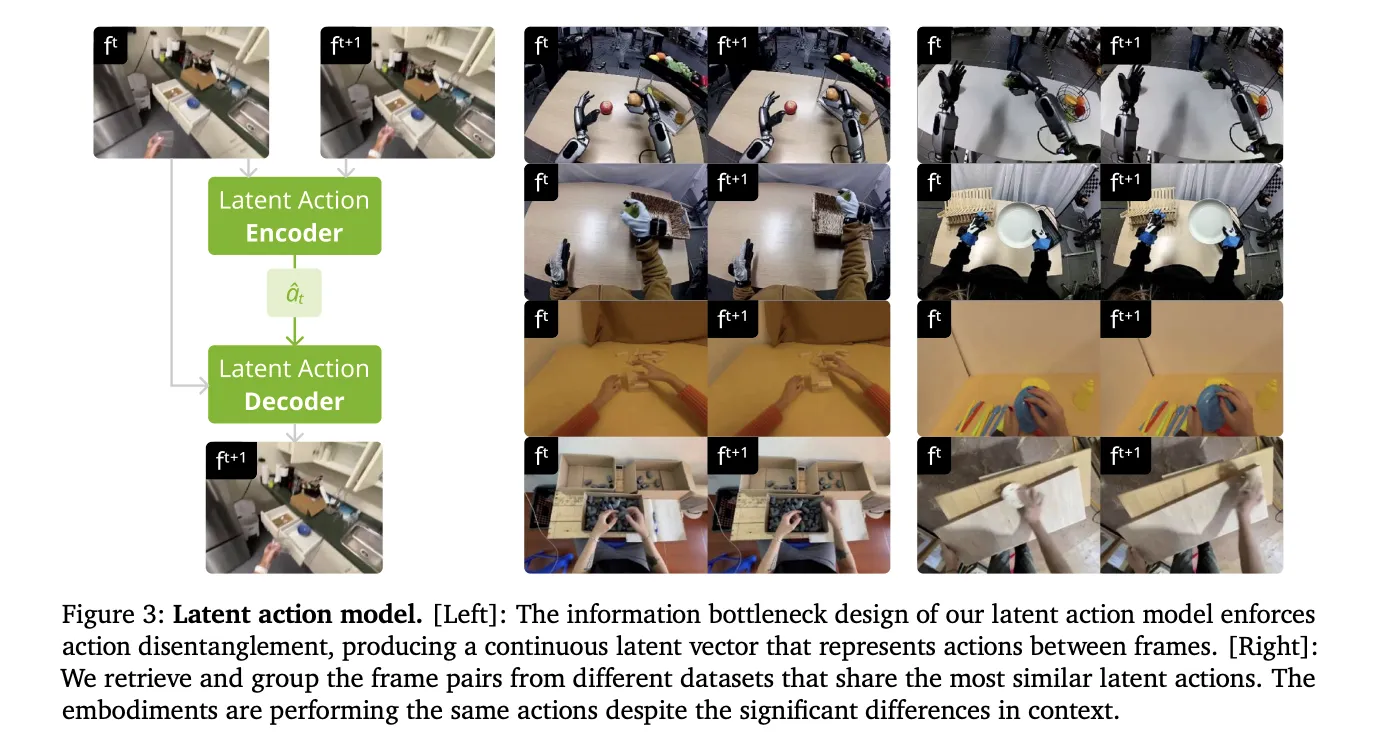


바이두의 PaddlePaddle 팀, PaddleOCR-VL (0.9B) 출시: NaViT 스타일 + ERNIE-4.5-0.3B VLM을 통한 end-to-end 다국어 문서 구문 분석
바이두의 PaddlePaddle 팀이 PaddleOCR-VL을 출시했습니다. 이 모델은 다국어 문서를 Markdown/JSON으로 변환하는데 사용되며, 텍스트, 표, 수식, 차트, 필기체 등을 구문 분석하는 데 적합합니다.
2025년 10월 17일 오전 4시 28분






















