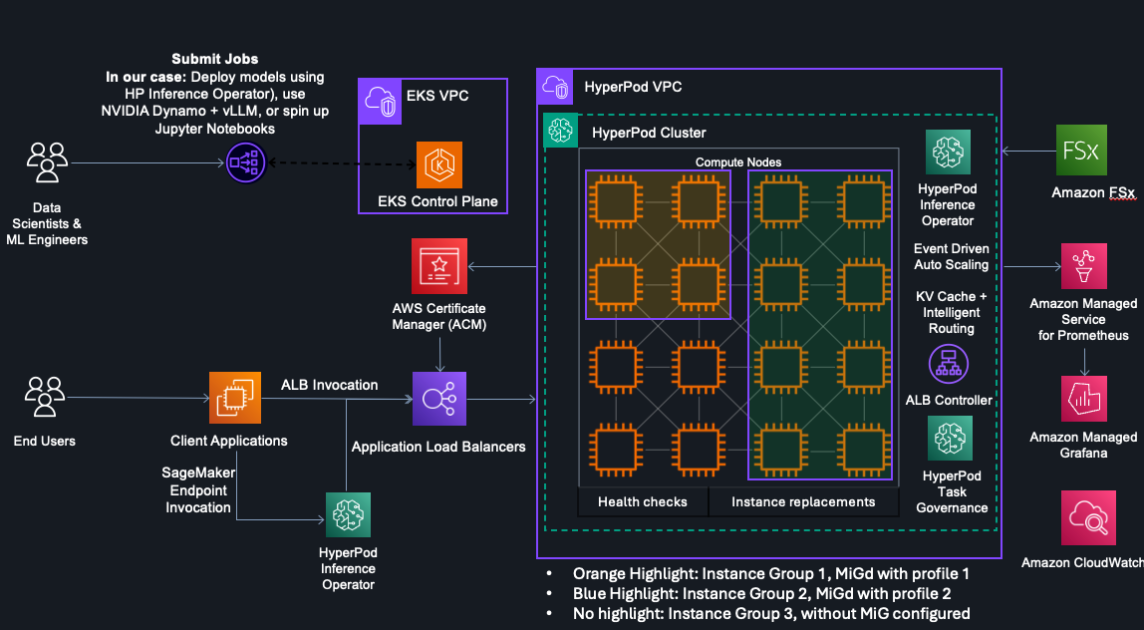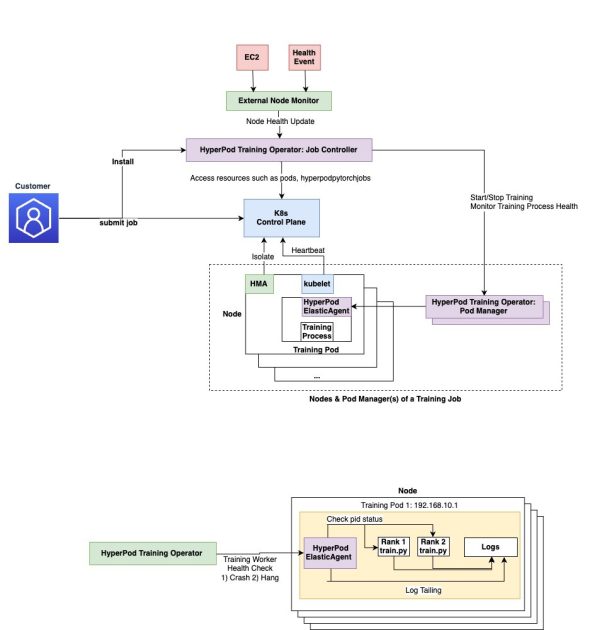

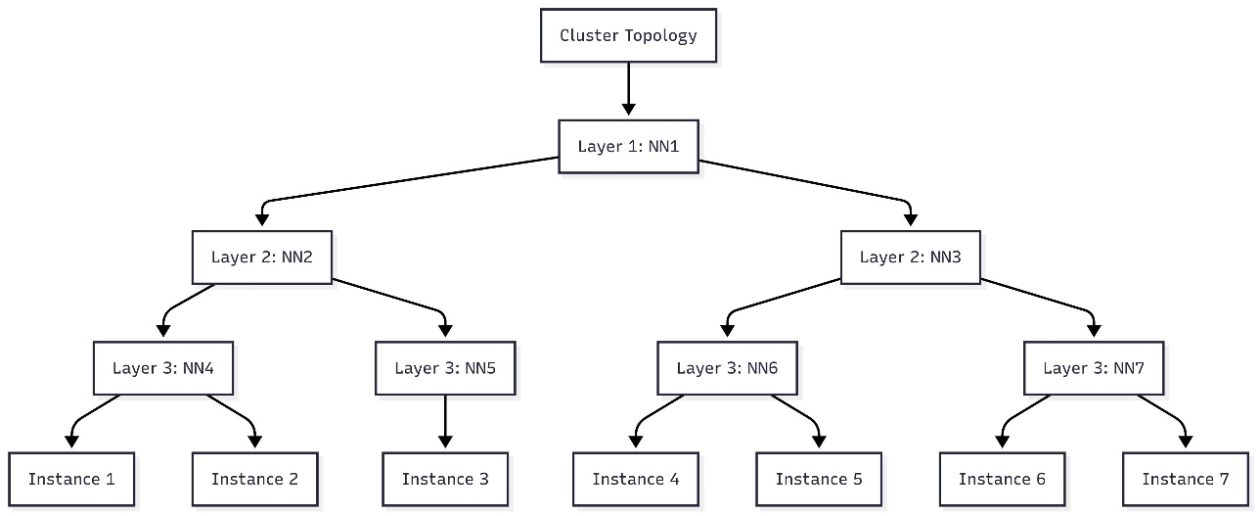

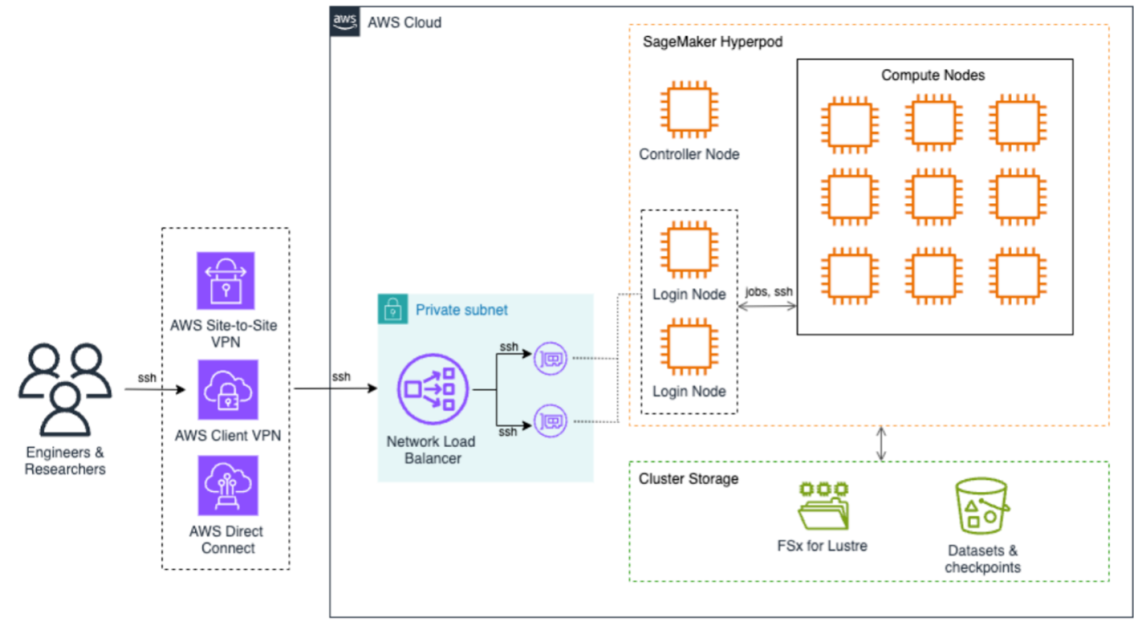







Amazon SageMaker HyperPod를 위한 관리형 Tiered KV 캐시 및 지능적 라우팅
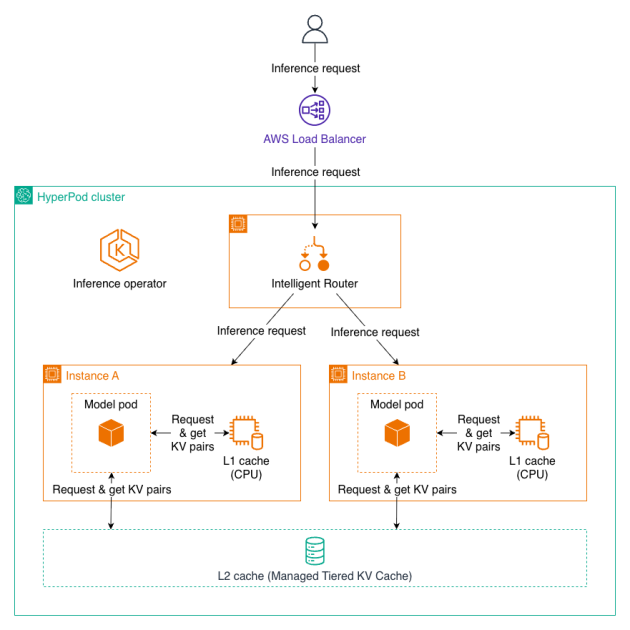
Amazon SageMaker HyperPod를 위한 관리형 Tiered KV 캐시 및 지능적 라우팅 기능 소개. 이 기능은 장문 프롬프트 및 다중 대화에서 최대 40%의 첫 토큰 시간 감소와 최대 25%의 컴퓨팅 비용 절감을 제공한다. 이 기능은 분산된 KV 캐싱 인프라와 지능적인 요청 라우팅을 자동으로 관리하여 엔터프라이즈급 성능으로 제품 규모의 LLM 추론 워크로드를 배포하는 것을 쉽게 하며 운영 오버헤드를 크게 줄인다.