




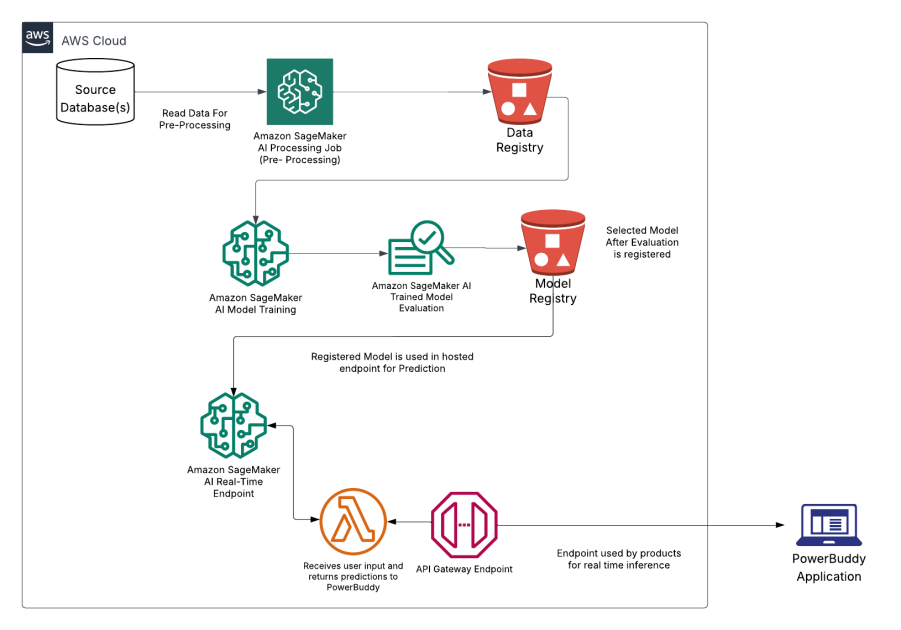
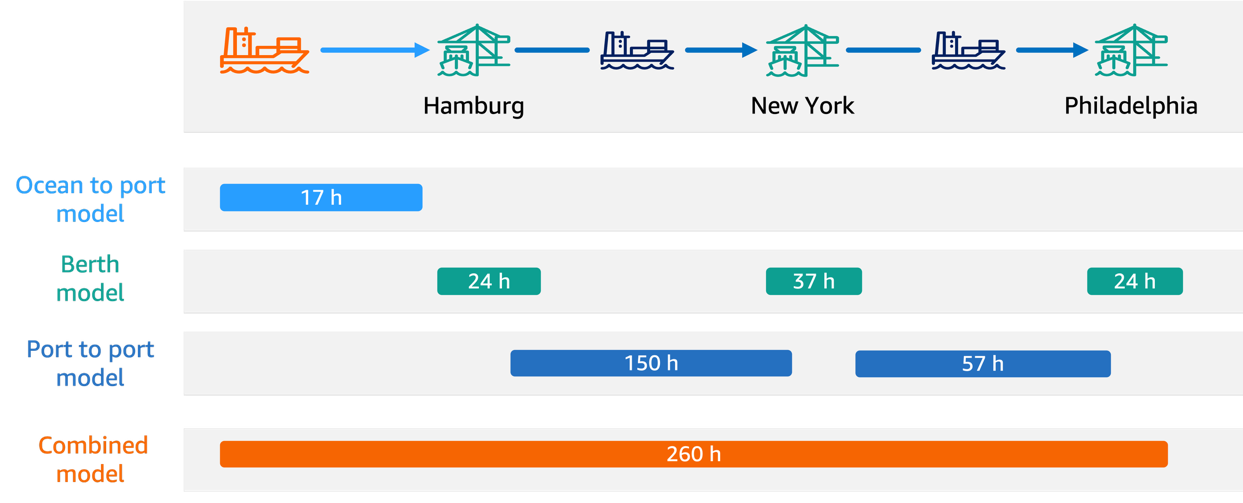


대규모 모델 추론 컨테이너 – 최신 기능 및 성능 향상
AWS는 최근 대규모 모델 추론(LMI) 컨테이너에 중요한 업데이트를 발표했다. 이 업데이트는 AWS에서 LLM을 호스팅하는 고객들을 위해 포괄적인 성능 향상, 확장된 모델 지원 및 간소화된 배포 기능을 제공한다. 이번 업데이트는 인기 있는 모델 아키텍처 전반에 걸쳐 운영 복잡성을 줄이고 측정 가능한 성능 향상을 제공하는 데 초점을 맞췄다.