
UCLA, AWS 생성 AI 서비스로 몰입형 극장 경험 제공
UCLA의 OARC 및 REMAP 팀이 AWS의 서버리스 인프라, 관리형 서비스 및 생성 AI 서비스를 활용하여 솔루션을 신속하게 설계하고 배포하는 방법을 설명하며, Amazon SageMaker AI의 사용법과 몰입형 실시간 경험에서 안정적으로 활용하는 방법을 소개합니다.
UCLA의 OARC 및 REMAP 팀이 AWS의 서버리스 인프라, 관리형 서비스 및 생성 AI 서비스를 활용하여 솔루션을 신속하게 설계하고 배포하는 방법을 설명하며, Amazon SageMaker AI의 사용법과 몰입형 실시간 경험에서 안정적으로 활용하는 방법을 소개합니다.
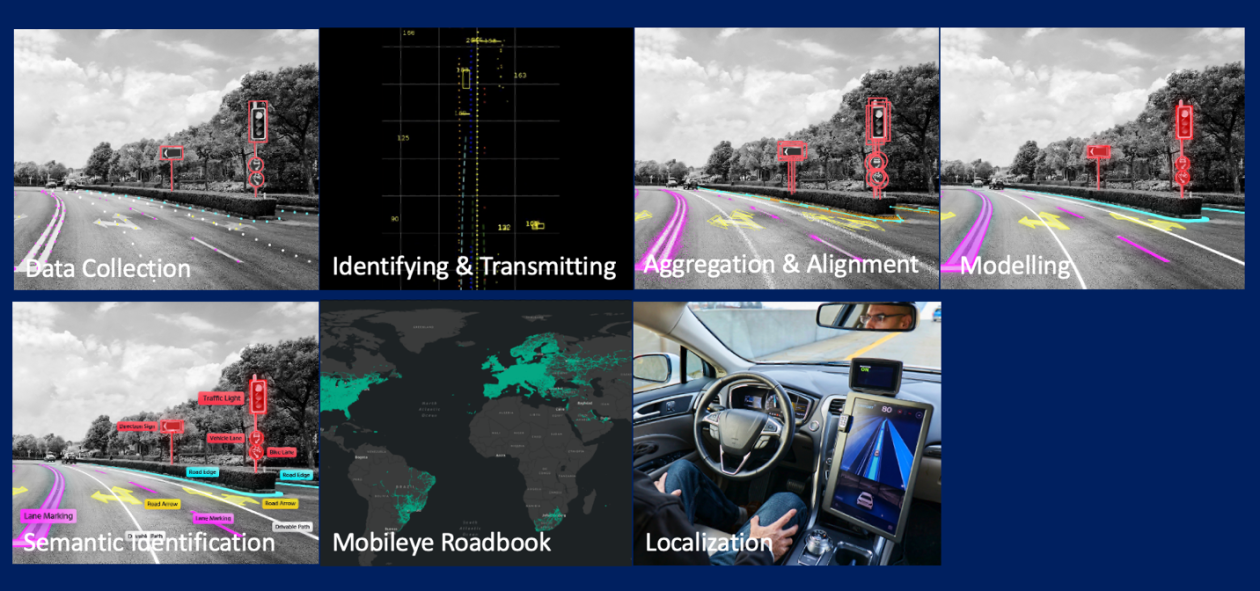
Mobileye 팀은 AWS Graviton을 활용하여 REM™을 최적화하는 방법에 대해 설명합니다. 이를 통해 ML 추론과 Triton 통합에 초점을 맞추고 있습니다.
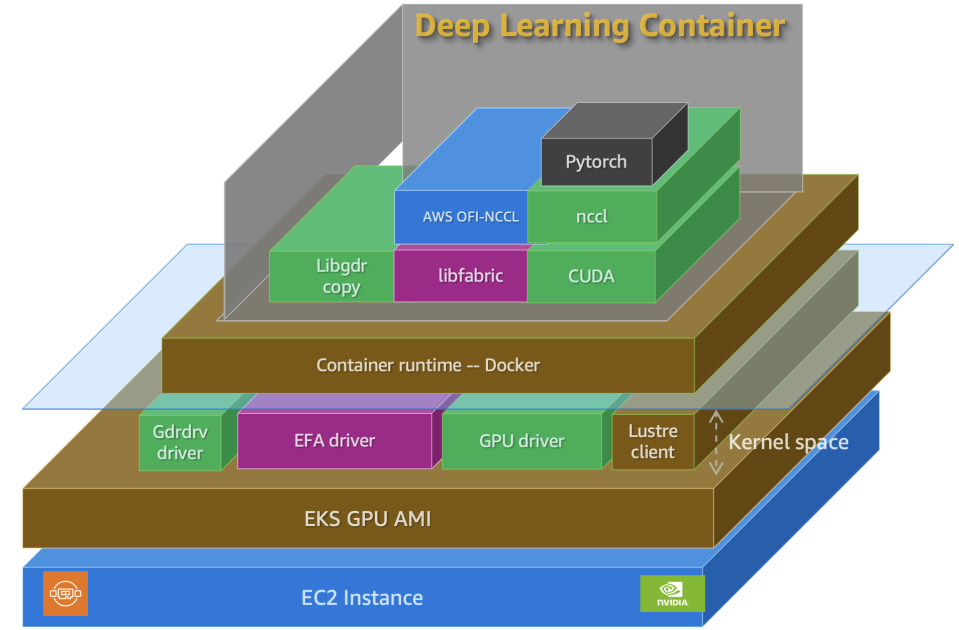
Amazon EKS에서 분산 학습 시 발생할 수 있는 구성 오류를 방지하기 위해 필요한 구성 요소를 시작하고 적절한 구성을 확인하는 체계적 접근 방법을 소개합니다. 이 게시물에서는 DLC를 사용하여 대규모 모델을 학습하기 위한 EKS 클러스터를 설정하고 확인하는 단계를 안내합니다.

아마존 EC2 P6e-GB200 UltraServers와 P6-B200 인스턴스의 일반 공급을 발표하며, NVIDIA Blackwell GPU를 사용하여 가장 크고 정교한 AI 모델의 교육 및 배포에 적합한 솔루션을 소개합니다.
Low-Rank Adaptation (LoRA)를 사용하여 동시성 모델 호스팅의 도전을 효과적으로 해결하는 방법을 살펴본다. LoRA 서빙과 LoRA 교환을 함께 사용하여 Amazon EC2 GPU 인스턴스로 LoRAX를 실행함으로써 조직이 세밀하게 조정된 모델 포트폴리오를 효율적으로 관리하고 제공하는 방법을 논의한다.
이 포스트는 비용 효율적이고 고성능 추론을 위해 AWS Inferentia2 인스턴스에 Mixtral 8x7B 언어 모델을 배포하고 제공하는 방법을 보여줍니다. Hugging Face Optimum Neuron을 사용한 모델 컴파일 및 Text Generation Inference (TGI) Container를 통해 LLMs를 배포하고 제공하는 방법을 안내합니다.