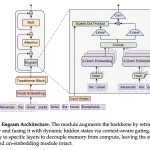
OpenAI, 콘텍스트 인식 취약점 탐지 및 패치 생성을 위한 Codex Security 연구 미리보기 소개
OpenAI가 Codex Security를 소개했습니다. 이는 코드베이스를 분석하여 취약점을 확인하고 개발자가 수정 전에 검토할 수 있는 보안 에이전트입니다. 제품은 ChatGPT Enterprise, Business 및 Edu 고객을 대상으로 연구 미리보기로 롤아웃 중입니다.
2026년 3월 6일 오후 3시 49분