

아마존 렉스 다중 개발자 CI/CD 파이프라인으로 조직 성장 촉진하기
본문에서는 아마존 렉스를 위한 다중 개발자 CI/CD 파이프라인을 소개하며, 격리된 개발 환경, 자동화된 테스트, 그리고 간편한 배포를 가능하게 합니다. 이 솔루션을 설정하는 방법과 이를 사용하는 팀들의 현실적인 결과를 공유합니다.







본문에서는 아마존 렉스를 위한 다중 개발자 CI/CD 파이프라인을 소개하며, 격리된 개발 환경, 자동화된 테스트, 그리고 간편한 배포를 가능하게 합니다. 이 솔루션을 설정하는 방법과 이를 사용하는 팀들의 현실적인 결과를 공유합니다.

아마존 노바는 대화 분석, 통화 분류 등 콜센터 솔루션에 관련된 다양한 사용 사례에서 뛰어난 성능을 보여준다. 단일 통화와 다중 통화 분석 사례에 대한 기능을 살펴본다.

아마존 AMET 결제팀은 단일 에이전트 AI 시스템의 한계를 극복하기 위해 인간 중심 접근 방식을 통해 구조화된 출력을 구현하고, 환각 현상을 크게 줄이며, AMET QA 팀 전반에 확장 가능한 솔루션을 구축했으며, 이후 국제 신흥 스토어 및 결제 (IESP) 조직의 다른 QA 팀 전반에 확장될 예정입니다.

Amazon Bedrock의 Foundation Models(FMs)와 Amazon Bedrock AgentCore를 사용하여 W&B Weave와 함께 기업용 AI 솔루션을 구축, 평가 및 모니터링하는 방법을 소개. 개별 FM 호출 추적부터 복잡한 에이전트 워크플로우 모니터링까지 전체 개발 주기 다룸.
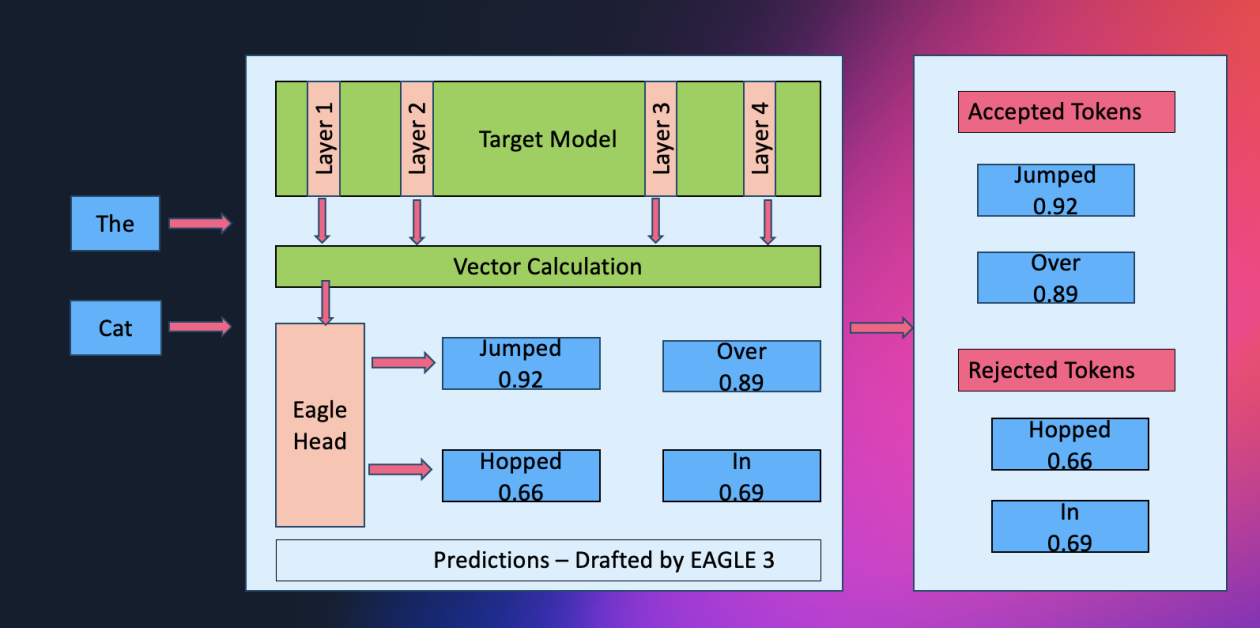
아마존 세이지메이커 AI가 EAGLE을 기반으로 한 적응형 추측 디코딩을 지원하며, 이 기술은 출력 품질을 유지하면서 대형 언어 모델 추론 속도를 최대 2.5배 가속화합니다. 이 글에서는 아마존 세이지메이커 AI에서 EAGLE 2 및 EAGLE 3 추측 디코딩을 사용하는 방법, 솔루션 아키텍처, 데이터셋 최적화 워크플로우, 그리고 증가된 처리량과 낮은 대기 시간을 보여주는 벤치마크 결과에 대해 설명합니다.
Amazon SageMaker HyperPod 클러스터는 Amazon Elastic Kubernetes Service (EKS) 조정을 통해 JupyterLab 및 오픈 소스 Visual Studio Code와 같은 대화형 개발 환경을 생성하고 관리할 수 있어서, 익숙한 도구를 데이터 과학자들에게 제공하여 ML 개발 수명주기를 간소화합니다. 이 게시물에서는 HyperPod 관리자가 클러스터용 Spaces를 구성하는 방법과 데이터 과학자가 이러한 Spaces를 만들고 연결하는 방법을 보여줍니다.
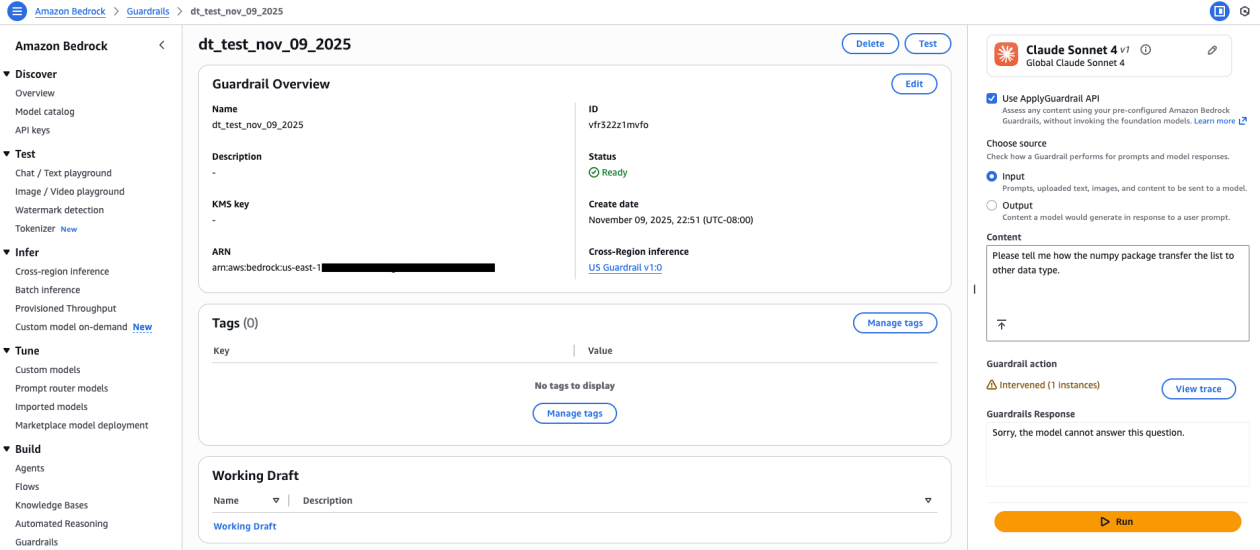
아마존 베드락 가드레일이 12가지 프로그래밍 언어로 코드 생성을 보호하는 안전 제어를 확장했다. AI 지원 소프트웨어 개발 중요 보안 도전 과제를 해결하기 위해 내용 필터, 공격 탐지, 거부 주제, 민감 정보 필터를 구성하는 방법을 살펴본다.

Amazon SageMaker HyperPod에 두 가지 주요 기능이 도입되어 대규모 머신 러닝 인프라의 보안 및 저장 기능이 강화되었습니다. 새로운 기능으로는 기업이 제어하는 암호화 키를 사용하여 EBS 볼륨을 암호화하는 고객 관리 키(CMK) 지원 및 AI 워크로드에서 Kubernetes 볼륨에 대한 동적 저장소 관리를 지원하는 Amazon EBS CSI 드라이버 통합이 포함됩니다.

아마존 베드락 배포를 위한 고급 비용 모니터링 전략을 탐색하며, 정확한 비용 할당을 위한 세밀한 사용자 정의 태깅 방법과 선제적 비용 관리 기초를 높이는 포괄적인 보고 메커니즘을 소개합니다. 이 솔루션은 호출 수준 태깅, 응용 프로그램 추론 프로필 및 AWS Cost Explorer 통합을 구현하여 생성적 AI 사용 및 비용의 완전한 360도 조망을 제공합니다.
이 글에서는 아마존 베드락 추론 비용을 선제적으로 관리하기 위한 종합적인 솔루션을 소개하며, 비용 센트리 메커니즘을 통해 기관에 발생할 수 있는 AI 비용을 효과적으로 제어하는 프레임워크를 제공합니다. 서버리스 워크플로우와 네이티브 아마존 베드락 통합을 활용하여 예측 가능하고 효율적인 접근 방식을 제공하며, 선행 지표와 실시간 예산 강제 실행을 통해 급증하는 비용을 방지합니다.
Amazon Bedrock에서 가져온 모델에 로그 확률이 어떻게 작용하는지 알아봅니다. 로그 확률의 개념, API 호출에서 활성화하는 방법, 반환된 데이터 해석 방법을 배우고, 잠재적 환각 감지부터 RAG 시스템 최적화 및 세밀하게 조정된 모델 평가에 이르기까지 이러한 통찰력이 AI 애플리케이션을 개선하는 방법을 강조합니다.
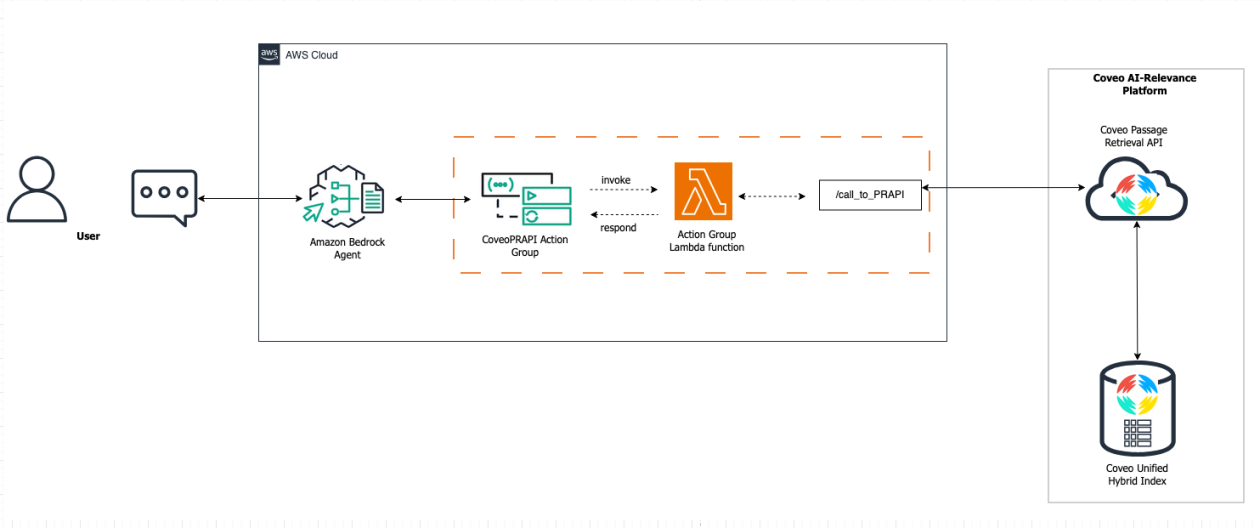
Coveo의 Passage 검색 API를 Amazon Bedrock 에이전트 액션 그룹으로 배포하여 응답 정확도를 향상시키는 방법 소개. Coveo 사용자는 현재의 색인을 활용하여 조직 전반에 새로운 생성 경험을 신속하게 배포할 수 있음.

이 블로그 포스트에서는 Amazon Bedrock를 통해 제공되는 Amazon Nova 모델을 사용하여 KIE 솔루션을 구축하고 평가하는 종단간 접근 방식을 시연합니다. 데이터 준비, 솔루션 개발, 성능 측정이라는 세 가지 핵심 단계를 포함하며, FATURA 데이터 세트를 사용하여 포괄적인 방법을 설명합니다.

SageMaker HyperPod의 세 가지 기능 소개. Continuous provisioning으로 유연한 리소스 프로비저닝 제공해 모델 학습 및 배포를 빠르게 시작하고 클러스터를 효율적으로 관리. Custom AMIs로 ML 환경을 조직의 보안 표준과 소프트웨어 요구 사항에 맞게 조정 가능.
아마존 베드락을 활용해 계정 계획 프로세스를 간소화하고 향상시킨 Account Plan Pulse를 소개합니다. Pulse는 검토 시간을 줄이고 협업과 소비를 위해 실질적인 계정 계획 요약을 제공하여 AWS 영업팀이 고객에게 더 나은 서비스를 제공할 수 있게 도와줍니다.
아마존 베드락 데이터 자동화와 세이지메이커 AI를 사용하여 다중 페이지 문서에 인간 검토 루프를 적용하는 방법을 소개합니다.
이 글에서는 강의 개요 생성과 강의 콘텐츠 생성이라는 두 가지 핵심 모듈의 기술적 구현과 함께 각 구성 요소를 자세히 탐구합니다.
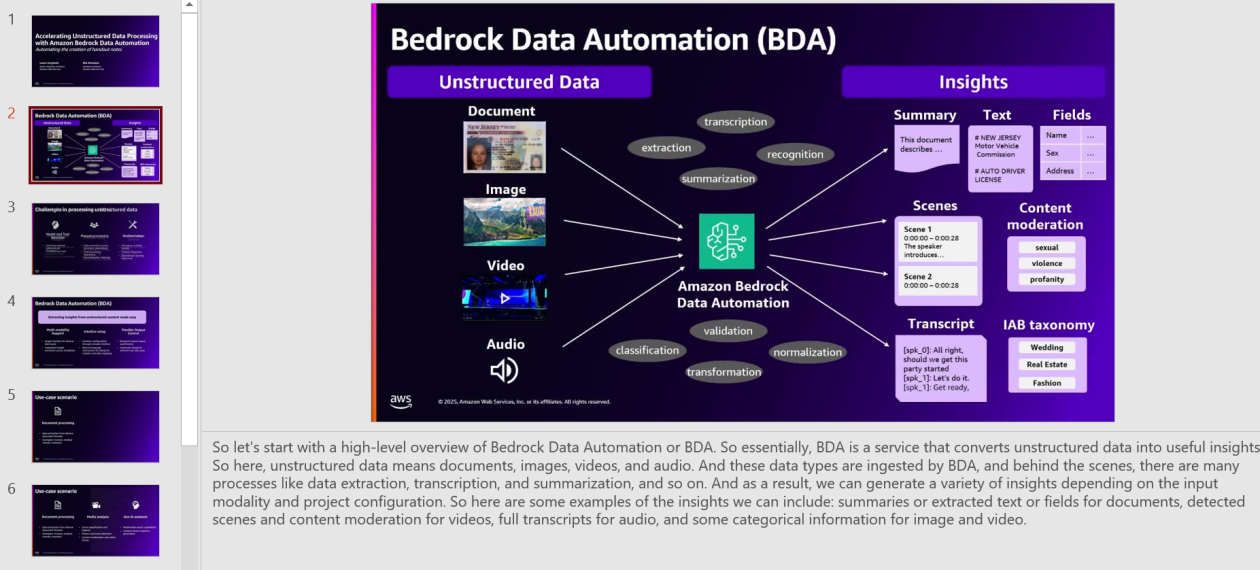
이 글에서는 Amazon Bedrock Data Automation을 사용하여 웨비나 녹화물을 종합적인 핸드아웃으로 변환하는 자동화된 서버리스 솔루션을 구축하는 방법을 소개합니다. Amazon Bedrock Data Automation을 구현하여 영상 분석을 위해 트랜스크라이브하고 슬라이드 변경을 감지하며, Amazon Bedrock foundation 모델 (FM) 및 사용자 정의 AWS Lambda 함수를 AWS Step Functions에 의해 조정하는 과정을 안내합니다.
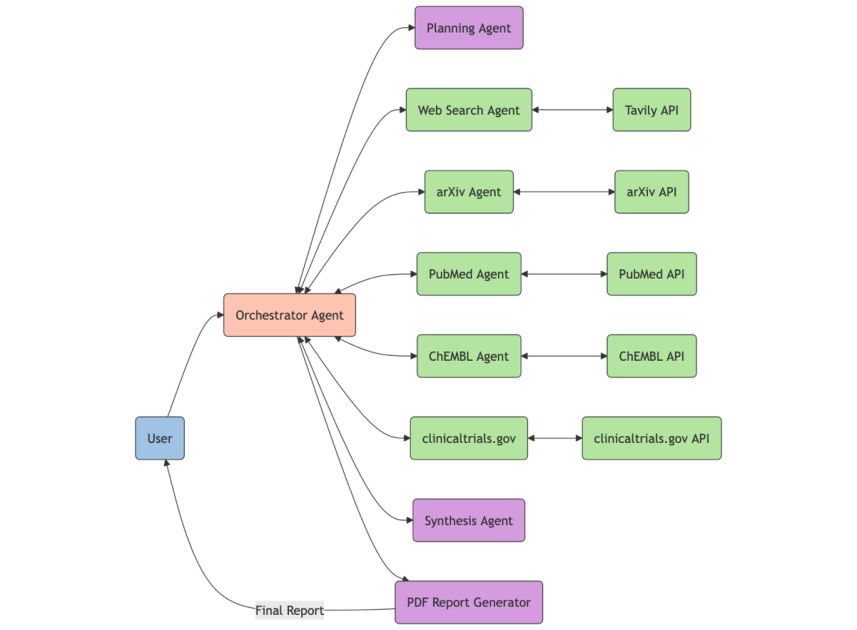
Strands 에이전트와 아마존 베드락을 이용하여 약물 발견을 위한 강력한 연구 보조 도구를 만드는 방법을 소개합니다. 이 AI 보조 도구는 Model Context Protocol (MCP)을 사용하여 여러 과학 데이터베이스를 동시에 검색하고, 그 결과를 종합하여 약물 타겟, 질병 메커니즘, 치료 분야에 대한 포괄적 보고서를 생성할 수 있습니다.
이 블로그 포스트는 Amazon Bedrock 데이터 자동화 및 기타 AWS 서비스를 이용한 종단 간 IDP 애플리케이션을 소개합니다. 이 애플리케이션은 IDP 파이프라인을 배포하고 문서를 구조화된 테이블로 변환하는 직관적인 UI를 제공하는 재사용 가능한 AWS 인프라를 제공합니다. 사용자는 입력 문서(계약서 또는 이메일 등)와 추출할 속성 목록만 제공하면 됩니다. 그럼 생성 AI를 사용하여 IDP를 수행합니다.

이 포스트에서는 Amazon Q를 QuickSight에 통합하여 “지난 6개월 동안 미국에서 반품된 상품 수를 보여줘”와 같은 자연어 요청을 의미 있는 데이터 시각화로 변환하는 방법에 대해 다룹니다. Amazon Bedrock 에이전트와 Amazon Q를 결합하여, 기업 전반에 걸쳐 데이터 액세스를 민주화하는 포괄적인 데이터 어시스턴트를 만드는 방법을 보여줍니다.

이 포스트에서는 Amazon Q CLI를 AWS Cost Analysis MCP 서버와 함께 사용하여 AWS 최상의 실천 방법을 따르는 정교한 비용 분석을 수행하는 방법을 탐색합니다. 기본 설정과 고급 기술, 자세한 예제 및 단계별 지침에 대해 설명합니다.

아마존 세이지메이커 캔버스는 노코드 솔루션을 제공하여 데이터 전처리를 간편화하고 기술적 배경이 없는 사용자도 시계열 예측이 가능하게 합니다. 이 글에서는 세이지메이커 캔버스와 데이터랭글러가 제공하는 노코드 데이터 준비 기술을 탐구하며 모든 배경을 가진 사용자들이 자신감을 가지고 데이터를 준비하고 시계열 예측 모델을 구축할 수 있도록 돕는 방법을 살펴봅니다.

도쿄 과학 연구소가 아마존 세이지메이커 하이퍼팟을 사용하여 70억 개의 파라미터를 가진 일본어 능력이 향상된 대형 언어 모델 Llama 3.3 Swallow을 성공적으로 훈련시켰다. 이 모델은 GPT-4o-mini 및 다른 선두 모델을 능가하는 일본어 작업에서 우수한 성능을 보여준다. 이 기술 보고서는 프로젝트 중 개발된 훈련 인프라, 최적화 및 모범 사례를 상세히 설명한다.

OpenSearch는 다양한 제3자 머신러닝(ML) 커넥터를 제공하여 이를 지원합니다. 이 포스트에서는 Amazon Comprehend 커넥터와 Amazon Bedrock 커넥터 두 가지를 소개합니다. Amazon Comprehend 커넥터를 사용하여 LangDetect API를 호출해 문서의 언어를 감지하는 방법과 Amazon Bedrock 커넥터를 사용하여 Amazon Titan Text Embeddings v2 모델을 호출하여 문서로부터 임베딩을 생성하고 의미 검색을 수행하는 방법을 보여줍니다.

LlamaIndex 프레임워크를 활용하여 에이전틱 RAG 애플리케이션을 구축하는 예시를 소개합니다. 이 애플리케이션은 Mistral Large 2 FM을 활용해 에이전트 플로우에 대한 응답을 생성하여 연구 도구로 활용됩니다.

아마존 노바 캔버스가 고급 이미지 생성 기술을 통해 실제 비즈니스 문제를 해결하는 방법을 탐구합니다. 이 기술의 강력함과 유연성을 보여주는 인테리어 디자인 및 제품 사진 촬영 두 가지 구체적인 사용 사례에 초점을 맞춥니다.

미디어 및 엔터테인먼트 산업에서 마케팅 캠페인의 효과를 이해하고 예측하는 것은 성공에 중요하다. 마케팅 캠페인은 성공적인 비즈니스의 주요 동력으로 작용하며, 새로운 고객을 유치하고 기존 고객을 유지하며 수익을 증대하는 데 중요한 역할을 한다. 그러나 캠페인을 시작하는 것만으로는 충분하지 않다. 이들의 영향력을 극대화하고 성공을 도와주기 위해…
이 포스트에서는 동영상 온디맨드 사례를 활용해 개별 사용자를 위한 맞춤형 아웃리치 이메일을 생성하는 방법을 Amazon Personalize 및 Amazon Bedrock을 사용하여 보여줍니다. 이 개념은 전자 상거래 및 디지털 마케팅 사례와 같은 다른 영역에도 적용할 수 있습니다.