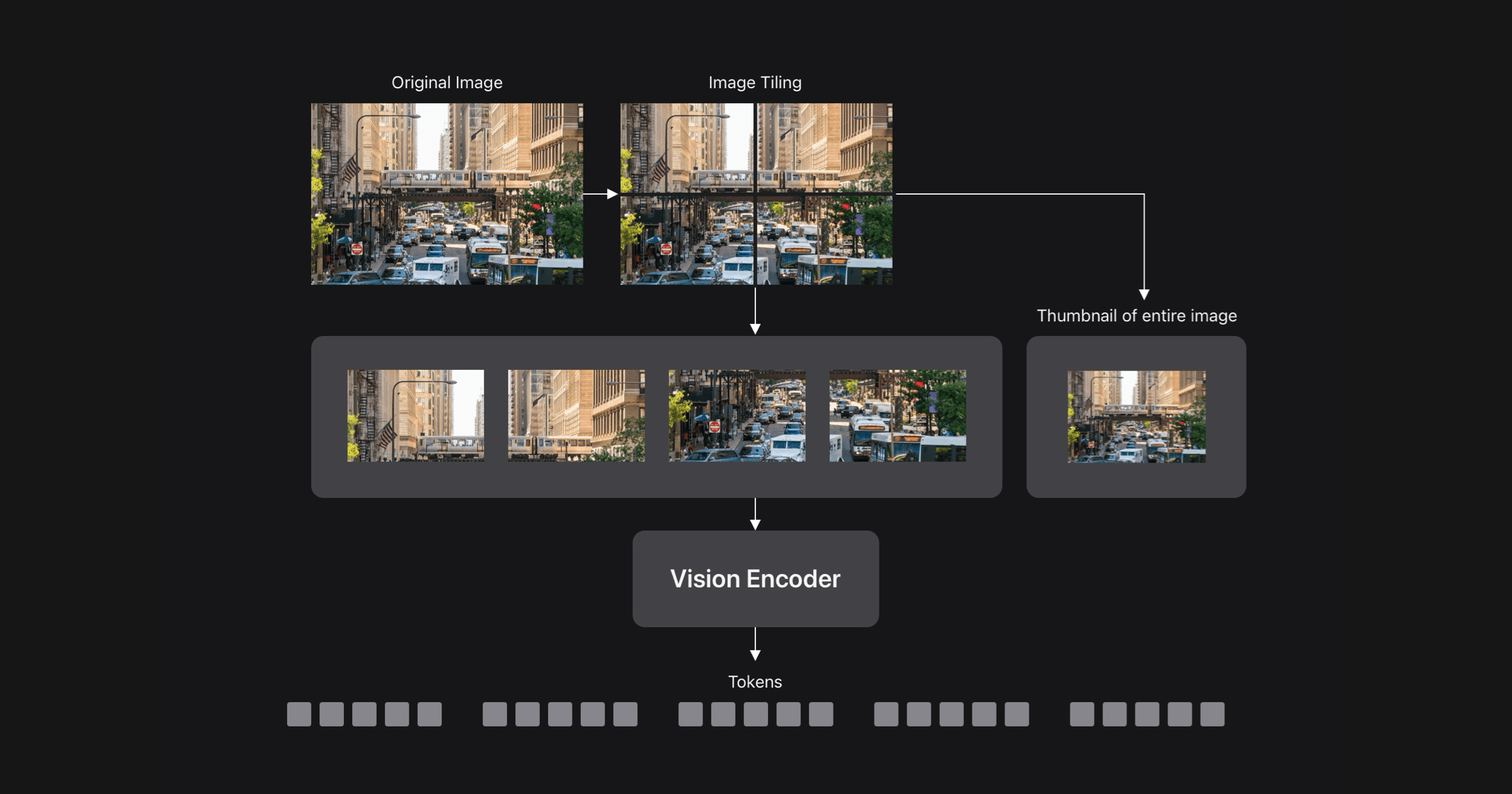
Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a pretrained vision encoder to a pretrained Large Language Model (LLM) through a projection layer. By leveraging the rich visual representations of the vision encoder and the world knowledge and reasoning capabilities of the LLM, VLMs can be useful for a wide range of applications, including accessibility assistants, UI navigation, robotics, and gaming. VLM accuracy generally improves with higher input image resolution, creating a tradeoff between accuracy and computational efficiency. FastVLM proposes an efficient vision encoding method to mitigate this tradeoff by incorporating a lightweight vision transformer that preserves high-resolution information. The approach achieves competitive performance on various VLM benchmarks while significantly reducing computational costs. FastVLM’s efficient vision encoding can enhance the applicability of Vision Language Models in real-world scenarios.